



游戏服务器网关该怎么设计?核心定位与职责边界全解析
最近在整理服务器架构,把网关这一层重新梳理了一遍。顺便分享下我们团队对于网关的一个设计。
网关的核心价值,是把连接层从业务里剥离出来,并在入口完成治理。
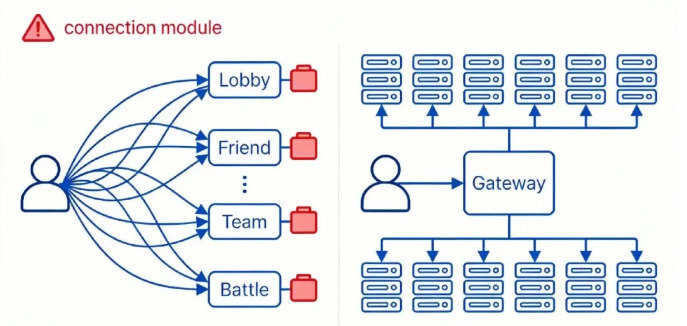
在现代的游戏服务器里,我们往往会把能力按边界拆开:网关服、大厅服、好友服、组队服、战斗服……每个服务独立迭代、独立扩缩容。拿我们项目来说,服务类型大概有 20 多种。拆分之后,整个游戏服务器集群更加复杂了,也就出现一个拆分就绕不开的问题摆到了台面上:外网连接与不可信流量,到底应该由谁来承接?
如果让客户端直连每个业务服,代价是把服务地址、协议细节、鉴权与路由规则都外溢到客户端;而客户端本质上不可控——代码可被逆向,协议可被模拟,请求可被篡改。最终,扩容/迁移/灰度的每一次调整,都可能演变成一次客户端改动,同时也失去了统一的入口治理点。
换个方向,你也可以让每个业务服直接对外维护长连接。听起来更“服务自治”,但工程代价更高:每个服务都要重复实现心跳、重连、拆包、限流、防刷、会话管理等一整套连接能力。入口问题被复制成 N 份,不仅轮子重复,策略难统一、风险会被放大:某个服务连接处理不好就可能先拖垮自己;外网流量一突刺,所有服务都要各自扛一轮冲击。最后系统会变成一种尴尬形态:业务服务本该专注业务,却被迫消耗大量精力在“连接基础设施”上。
所以网关真正解决的,不是“少写点代码”,而是两类长期成本的收敛:一类是后端拓扑变化带来的成本;另一类是外网长连接治理带来的成本。 为了把这两类成本收敛起来,我们需要一个统一入口承接外网连接,并把请求稳定地路由到门内服务——这就是网关(Gateway)。
网关本质是一台(或一组)服务器,职责应收敛在连接层,通常包含三件事:
- 连接管理:维持玩家与服务端的长连接(心跳、踢线、重连)
- 路由转发:接收玩家请求并转发到正确的后端服务
- 会话续接:断线重连后的必要恢复/补偿(按协议约定)
一句话概括:网关 = 连接管理 + 路由转发 + 会话续接。也正因为网关处在入口,它的设计目标应该是“轻量、稳定、可替换”,因此它不应承载业务规则与权威状态——否则入口会变重,故障半径和变更成本都会被放大。
我们在项目里踩过一次坑:曾让网关承担部分业务(例如聊天室房间管理)。后来做断线重连设计时发现,这会带来两类代价:1)入口资源被挤占:业务峰值与连接/转发争抢资源,转发延迟出现长尾(例如 转发P99 抬升,并伴随内部队列持续堆积)。
2)重连回包路径被撕裂:恢复需要收敛各业务服务的回包与状态补偿;网关一旦也产出业务回包,会让“回包收集与记录”分裂为两套:转发的回包和网关业务的回包。恢复时序难对齐,排查成本显著上升。
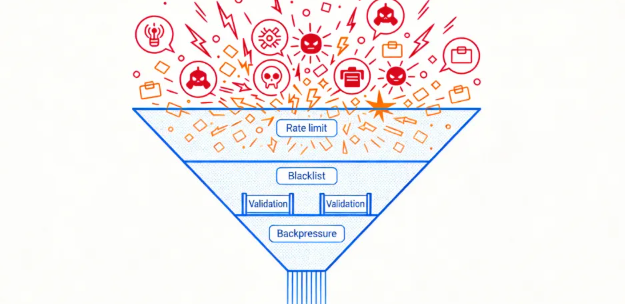
因此在最新一版网关设计中,我们重新钉死定位:网关是连接层与入口治理层,不是业务承载层,所有业务规则与权威状态下沉到游戏集群。它只保留必要的入口治理(连接数上限、限流/背压/快速失败、畸形包丢弃、黑白名单、token 合法性校验),用于第一跳削峰止损。
到这里,网关这一层的定位与边界就比较清楚了:它的任务是收敛连接与拓扑变化的长期成本,而不是承载业务。我们把网关保持在“连接管理 + 路由转发 + 会话续接(附带基础入口治理)”的范围内,本质是在控制入口的故障半径和变更成本,让系统能持续演进。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。