



Git 对象如何存储?Git 工作原理解析
当我们使用 Git 常见命令管理我们的代码时,命令背后到底发生了什么?文件存在哪?Git 又是怎么在不占太多空间的情况下记录每次修改的?
了解 Git 的内部机制可以帮助你更好地理解你的更改,更快地调试问题,并将 Git 用作它被设计成的强大工具。
本文将简明讲解:
- Git 底层到底是什么
- 核心对象:blob、树(tree)和提交(commit)
- Git 如何用 SHA-1 哈希存储和定位数据
- 三个关键区域:工作目录、暂存区、仓库
- 提交、分支、合并与变基的真实运作方式
- Git 为何能高效节省空间
1. 分布式版本控制
Git 是一个分布式版本控制系统,由 Linus Torvalds 于 2005 年创建,用于 Linux 内核开发。
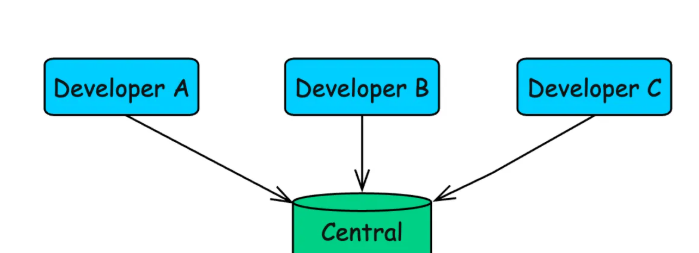
像CVS和SVN这样的老工具使用集中式模型:一个服务器保存着真理的源泉,开发人员从该中央机器拉取和推送代码。
Git 颠覆了这种模式。在 Git 中,每个开发者都拥有代码仓库的完整副本,包括完整的历史记录。
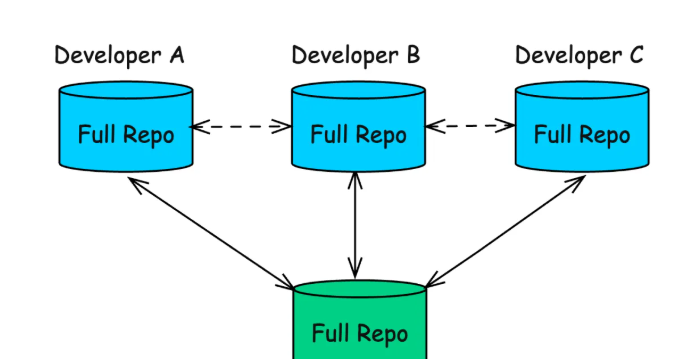
这种分布式架构为 Git 带来了一些关键优势:
- 离线工作,并保留完整历史记录
- 没有单点故障
- 由于大部分工作都在本地完成,因此操作速度更快。
- 适用于团队和个人的灵活工作流程
但是,Git 如何在不让代码库变得庞大的情况下存储完整的历史记录呢?要回答这个问题,你需要了解Git 的数据模型。
2. Git 的数据模型
Git 的核心是一个内容寻址文件系统。它将数据存储为对象,每个对象都由其内容的SHA-1 哈希值标识。
当你向 Git 添加文件时,它会计算该文件内容的 40 个字符的十六进制 SHA-1 哈希值。这个哈希值就成为该文件在 Git 数据库中的唯一地址。
File contents: "Hello, World!"SHA-1 hash: 5dd01c177f5d7d1be5346a5bc18a569a7410c2ef
相同的内容总是产生相同的哈希值。因此,内容完全相同的两个文件(即使文件名不同)具有相同的哈希值。
Git 将内容存储一次,并多次引用它,这有助于存储库即使在数千次提交后也能保持紧凑。
Git 将所有内容组织成对象并存储在其数据库中。对象有四种类型,但其中三种对于理解 Git 的工作原理至关重要:blob、树和提交。
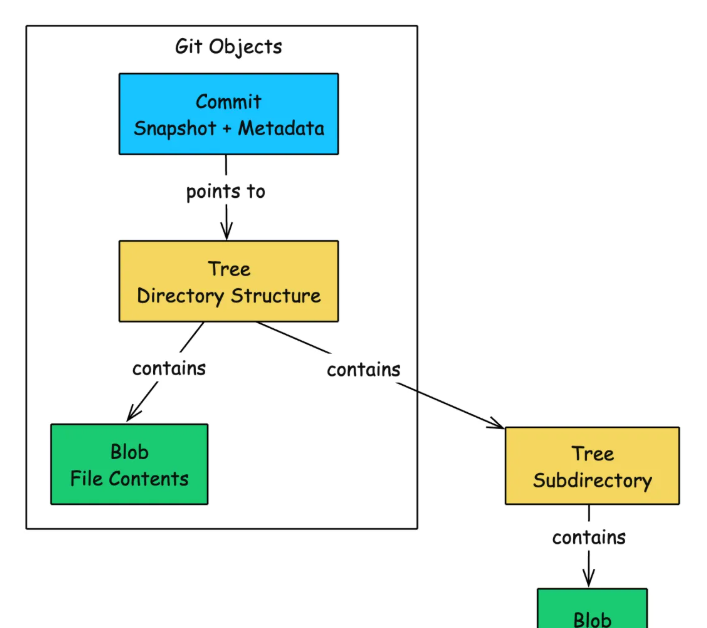
Blob:存储文件内容
blob (二进制大对象)存储文件的原始内容,仅包含文件内容,不包含文件名、权限、时间戳或任何类型的元数据。
当你向README.mdGit 添加文件时,它会创建一个包含文件文本的 blob。这个 blob 并不知道它来自一个名为 `.gitignore` 的文件README.md。它仅仅是一块字节块,并附有根据这些字节计算出的 SHA-1 哈希值。
为什么要将内容与文件名分开?
如果将同一个配置文件复制到三个位置,普通的系统会存储三份副本。而 Git 只存储一个数据块,并引用三次,这种存储空间节省会在项目历史记录中不断累积。
当然,即使 blob 不存储文件名,Git 仍然需要一种方法来表示文件夹结构。这就是tree的作用。
树状图:映射目录结构
树状结构代表目录。它包含指向 blob(文件)和其他树状结构(子目录)的指针,以及文件名和权限。
Tree: 4c5f8a2b9d3e7f1a6b0c8d5e2f9a4b7c3d6e0f1a├── README.md -> blob 5dd01c17... (100644)├── src/ -> tree 8a3b2c1d...└── package.json -> blob 7f2e3d4c... (100644)
这棵树充当目录列表。它显示“存在一个名为 README.md 的文件,其内容存储在 blob 5dd01c17 中”。blob 存储数据;树则为其命名并指定位置。
如果重命名文件而不更改其内容,Git 会创建一个指向同一数据块的新树(使用新文件名)。实际的文件数据不会被复制。
现在我们有了用于存储内容的二进制数据块(blob)和用于存储结构的树状文件(tree)。但版本控制需要更多:还需要记录谁做了更改、何时更改以及更改的原因。这就是提交(commit)机制所提供的。
提交:记录历史
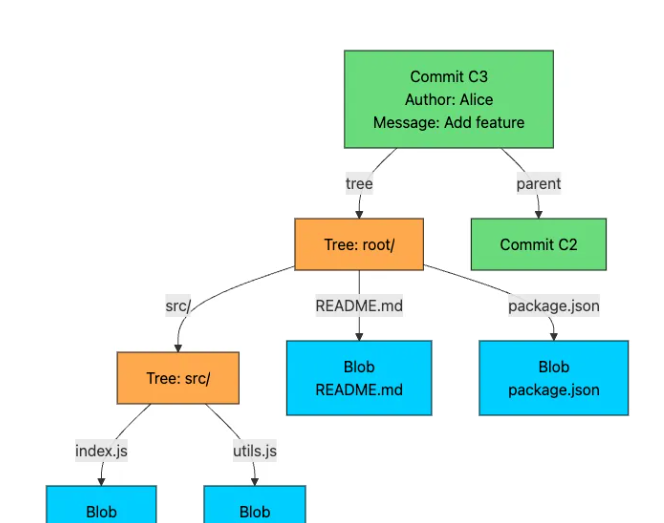
提交记录会捕捉项目在特定时间点的完整快照。每个提交都包含:
- 指向树状结构的指针(当前指向根目录)
- 指向父提交的指针(指向当前提交的历史记录)
- 作者信息(谁编写了这些更改)
- 提交者信息(谁进行了更改)
- 时间戳
- 解释更改的提交消息
Commit: abc123def456...tree: def456...parent: 789012...author: John <john@example.com> 1699900000 +0000committer: John <john@example.com> 1699900000 +0000Add login feature
当你运行`git commit` 命令时,Git 会创建一个新的提交对象。这个提交指向一个表示项目当前状态的树状结构。父指针指向上一个提交,形成一个链。这条链就是项目的历史记录。
父指针使 Git 成为版本控制系统而不仅仅是文件系统。通过追溯父指针,Git 可以重建项目的任何先前状态。
下图展示了 Git 对象模型中完整快照的样貌:
Git 拥有 blob、树和提交等一切所需,足以存储和跟踪你的项目。但这些对象实际存储在哪里呢?
3. Git 如何存储对象
运行`git init`时,Git 会创建.git具有以下结构的目录:
.git/├── HEAD (contains: ref: refs/heads/main)├── config (repository configuration)├── description (used by GitWeb, rarely relevant)├── hooks/ (scripts triggered by Git events)├── info/ (exclude patterns, other info)├── objects/ (the object database, initially empty)│ ├── info/│ └── pack/└── refs/ (references to commits)├── heads/ (branch pointers, initially empty)└── tags/ (tag pointers)
所有 Git 对象都存储在您的仓库.git/objects目录中。
Git 使用简单的组织方案:对象哈希的前两个字符成为子目录名称,其余 38 个字符成为文件名。
.git/objects/├── 5d/│ └── d01c177f5d7d1be5346a5bc18a569a7410c2ef (blob)├── 4c/│ └── 5f8a2b9d3e7f1a6b0c8d5e2f9a4b7c3d6e0f1a (tree)├── a1/│ └── b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0 (commit)└── ...
这个双字符前缀可以防止单个目录包含过多的文件,从而避免文件系统操作变慢。
在将对象写入磁盘之前,Git 还会使用 zlib 对其进行压缩。一个 1MB 的源文件可能会压缩到 100KB 甚至更小。再加上内容寻址去重(相同的内容只存储一次),即使拥有很长的历史记录,Git 仓库的大小也仍然非常小。
直接检查对象
Git 提供了一些底层命令来检查对象。这些“底层”命令揭示了其内部运行机制:
# Determine an object's type (blob, tree, commit, or tag)git cat-file -t 5dd01c17# Display an object's contentsgit cat-file -p 5dd01c17# Examine what a commit containsgit cat-file -p HEAD
尝试git cat-file -p HEAD在代码仓库中运行。你会看到树指针、父指针、作者信息和提交信息。然后git cat-file -p对该树哈希值运行命令,即可查看目录列表。
对象解释了 Git 如何存储数据,但尚未解释日常工作流程。当你编辑文件、暂存文件并提交时,数据会在三个不同的区域之间移动。
接下来我们来看看这些。
4. 三个领域
Git 将你的工作组织成三个不同的区域。理解这些区域是理解 Git 命令行为方式的关键。
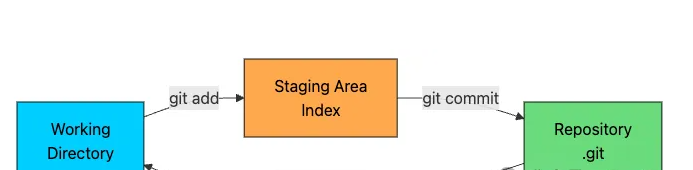
工作目录:您的工作区
工作目录就是你在文件资源管理器中看到的内容。这些是文件系统中实际存在的文件,你可以在编辑器中打开、修改和保存这些文件。
工作目录并非 Git 本身,它只是项目某个特定版本的检出目录。Git 可以在几秒钟内将其删除并从任何提交中重新创建。
这就是为什么即使在大型项目中,你也可以瞬间切换分支的原因。Git 并非移动文件,而是根据其对象数据库重新生成工作目录。
暂存区:您的草稿
暂存区(也称为索引)位于一个单独的文件中。它代表了您下一次提交将包含的.git/index内容的精确快照。
运行git add README.mdGit 时,它会执行两项操作:
- 根据文件的当前内容创建 blob 对象(如果内容匹配,则重用现有 blob 对象)。
- 更新索引,将文件名与该 blob 的哈希值关联起来。
把暂存区想象成你下次提交的草稿。你可以逐步添加文件到暂存区,也可以从中删除文件,并在提交之前仔细查看暂存区的内容。
这样你就可以精确控制每次提交的内容。
# See what is staged versus what is modifiedgit status# See the actual diff of staged changesgit diff --staged# Remove a file from staging (keep the working directory change)git restore --staged README.md
为什么要设置临时集结区?
假设你修改了五个文件。其中三个是修复bug的一部分,另外两个是无关的清理工作。
如果没有暂存环境,要么你一次性提交所有更改,要么就得手动费力地进行调整。有了暂存环境,你可以先提交错误修复,然后再单独提交清理工作。这样一来,你的提交历史记录就会保持清晰,易于追踪。
资料库:真理之源
仓库就是目录。它包含所有内容:对象数据库(所有 blob、树、提交)、引用(分支、标签)、配置、钩子等等。.git
当你运行git commit 命令时,Git:
- 根据当前索引创建树对象
- 创建一个指向该提交树的提交对象,并将当前 HEAD 作为其父节点。
- 更新当前分支以指向此新提交
代码仓库是项目的真实来源。工作目录和暂存区只是对它的一种便捷访问。如果您删除了工作目录但保留了代码仓库.git,您可以恢复所有内容。如果您删除了代码仓库.git,您的历史记录将丢失。
现在我们了解了数据存储在哪里,接下来让我们了解提交文件时实际会发生什么。
5. 如何提交工作
Git提交并不是“一系列更改的集合”。它是项目在某一时刻的快照,外加指向其父提交的指针。
让我们来追踪一下 Git 在提交时创建了什么。
创建你的第一个提交
echo "Hello" > hello.txtgit add hello.txtgit commit -m "Initial commit"
此时,Git 会写入三个对象:
- Blob :( )的内容hello.txt"Hello\n"
- 树:映射到该 blob 的目录列表hello.txt(并存储文件模式等信息100644)
- 提交:指向提交树并存储元数据(作者、时间戳、消息)
提交本身并不直接包含文件内容,而是包含指向根树的指针,而该根树又指向二进制数据块(blob)。
创建第二个提交
现在修改文件并再次提交:
echo "World" >> hello.txtgit commit -am "Add world"
Git内部发生了哪些变化?
- hello.txt由于有了新内容,Git 会为新内容创建一个新的 blob 。
- 因为该文件现在指向不同的数据块,所以 Git 创建了一个新的树。
- Git 会创建一个指向该新树的新提交,并将其父提交设置为上一个提交。
注意一下什么没有发生:
- Git 没有修改 Blob A。
- Git 没有覆盖树 A。
- Git 没有“更新”提交 A。
Git 对象实际上是不可变的。新的状态意味着新的对象,而未更改的对象则会被重用。
还要注意存储效率:尽管提交是“快照”,但 Git 并非每次都复制所有内容。只有发生更改的对象才会被更新,其他所有内容都会被重新引用。
快照,而非差异
一个常见的误解是,Git 会存储提交之间的差异,例如:
Commit 1 + Diff -> Commit 2 + Diff -> Commit 3 ...Git 的工作方式并非如此。
Git 存储快照:
- 每次提交都指向一棵树
- 该树状图代表了当时的完整目录状态
- Git 只会在你请求时计算差异(例如git diff,git showPR 查看)。
因此,内部模型更接近于这样:
Snapshot (Tree) A -> Commit ASnapshot (Tree) B -> Commit BSnapshot (Tree) C -> Commit C
这就是为什么类似这样的操作速度checkout很快。Git 不会从头开始重放每一次更改。它只会读取你所需的提交对应的提交树,并基于该快照重新生成工作目录。
6. 分支机构的运作方式
改变你对 Git 看法的事实是:分支只是指向提交的指针。
这就是全部实现过程。分支是一个包含 40 个字符的提交哈希值的小文件。你的分支文件main位于.git/refs/heads/main.
.git/refs/heads/main: a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0.git/refs/heads/feature: x9y8z7w6v5u4t3s2r1q0p9o8n7m6l5k4j3i2h1g0
创建分支几乎是瞬间完成的,因为 Git 只会创建一个很小的文件。它不会复制文件,也不会重复历史记录。它只会创建一个 41 字节的文件(40 个字符加一个换行符),指向一个已存在的提交。
标题:追踪您当前的位置
HEAD是一个特殊的引用,它告诉 Git 你当前所在的位置。在大多数情况下,HEAD 指向的是一个分支名称,而不是直接指向一个提交:
.git/HEAD: ref: refs/heads/main这意味着:“你当前位于main。” Git 通过以下指针解析你当前的提交:HEAD→ main→ 提交 → 树 → 文件
使用Git 分支功能创建新分支时,Git 会创建一个.git/refs/heads/feature包含当前提交哈希值的分支。不会创建新的提交,也不会复制现有内容。
当您使用git checkout 功能切换分支时,Git 会更新 HEAD 指向该分支refs/heads/feature,然后重新生成您的工作目录和索引以匹配该分支的提交。
有时 HEAD 指针会直接指向提交哈希值而不是分支名称。这称为分离 HEAD状态。当您通过哈希值检出特定提交或检出标签时,就会发生这种情况。
在这种状态下,您创建的任何新提交都不会附加到分支上,如果您在未创建分支来保存它们的情况下切换到其他分支,则可能会“丢失”。
如何提交高级分支
在分支上创建新提交时,Git 会将分支指针向前移动。
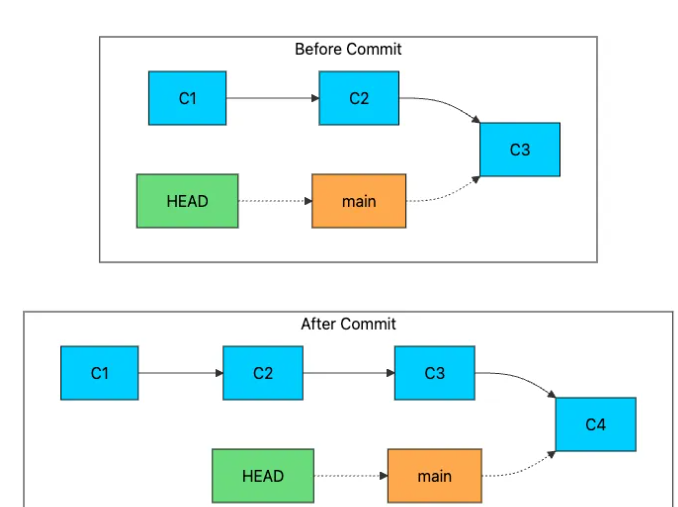
新的提交(C4)以 C3 为父提交。然后 Git 更新.git/refs/heads/main以包含 C4 的哈希值。HEAD 仍然指向 main,但 main 现在指向了新的提交。
这种基于指针的设计解释了为什么 Git 分支如此快速且成本低廉。它不涉及任何复制操作。从同一个提交创建十个分支意味着创建十个 41 字节的文件,所有文件都指向同一个提交哈希值。
但分支会分岔。不同的开发者会在不同的分支上进行不同的修改。最终,这些分支需要合并。让我们来看看合并是如何进行的。
7. 合并流程
合并操作将两个分支的工作合并成一个分支。Git 会根据分支的差异程度采用不同的合并处理方式。
快速合并:简单案例
最简单的合并发生在目标分支自源分支创建以来没有移动的情况下。在这种情况下,Git 会执行快进合并:它只是简单地将目标分支指针向前移动,使其与源分支的指针对齐。
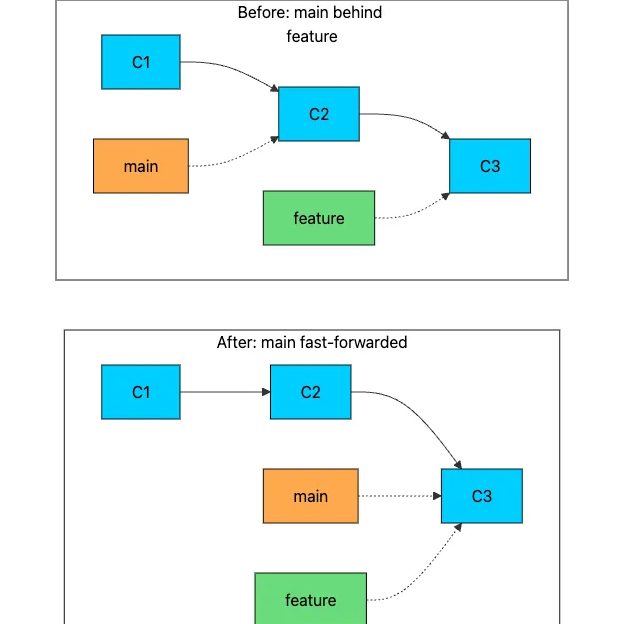
不会创建新的提交。Git 只是将主分支指针从 C2 更新为 C3。快速合并是即时的,并且会创建线性历史记录。
三岔路口合并:当分支分叉时
当两个分支自分叉以来都有新的提交时,Git 会执行三路合并。它需要三项信息:
- 合并基点:分支分化的共同祖先
- 当前分支提示:您的分支现在位于(我们的)哪个分支?
- 另一个分支提示:你要合并的内容(他们的)
Git 会将两个分支的末端与合并基准进行比较,以确定每一侧的更改。仅出现在一侧的更改会自动应用。冲突的更改(双方都修改了相同的行)需要手动解决。
合并后的提交(C4)有两个父提交:来自主分支的 C2 和来自特性分支的 C3。这保留了两个分支的完整历史记录。您可以追溯到任一父提交,以查看每个分支上发生的具体工作。
处理冲突
当 Git 无法自动合并(同一行代码在双方修改方式不同)时,它会在文件中标记冲突:
<<<<<<< HEADconst timeout = 5000;=======const timeout = 10000;>>>>>>> feature
<<<<<<< HEAD介于两者之间的所有内容=======均来自您当前分支。介于两者之间的所有内容=======均>>>>>>> feature来自要合并的分支。
您可以通过编辑文件以包含您实际想要的内容、删除冲突标记、然后暂存和提交来解决冲突。
合并操作会保留两个分支的完整历史记录,但会创建合并提交,这可能会使历史记录变得混乱。还有另一种集成更改的方法,可以生成更清晰、更线性的历史记录。
8. 变基的工作原理
变基是合并的替代方法,它会重写历史记录,从而创建线性提交序列。
rebase 不是创建将两个分支连接在一起的合并提交,而是将你的提交移动到目标分支之上,使它们看起来像是在目标分支之上创建的。
当你在特性分支上运行git rebase main时,Git:
- 找到两个分支的共同祖先
- 保存特性分支特有的提交
- 将分支重置到主分支的顶端
- 逐个重放你保存的提交记录。
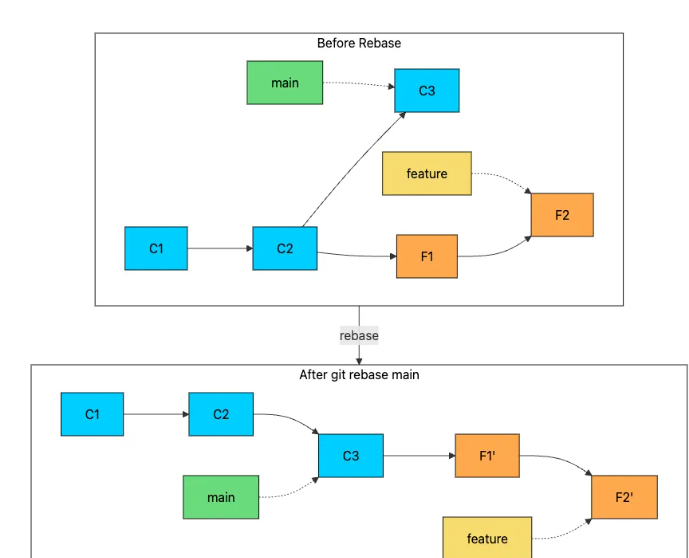
请注意,变基后,F1 和 F2 分别变成了 F1' 和 F2'。撇号表示这是两个新的提交,它们的哈希值不同。尽管更改内容完全相同,但这些提交的父指针不同,这意味着它们的 SHA-1 哈希值也不同。
原始提交仍然存在于对象数据库中(并且可以通过 reflog 恢复),但已无法从任何分支访问。
9. Git 如何优化存储
到目前为止,我们讨论的都是“散乱对象”:即.git/objects/用哈希值命名的单个文件。这种方法编写新对象既简单又快捷,但扩展性并不理想。
随着代码库的增长,会出现两个问题:
- 文件系统开销:成千上万(甚至数百万)个小文件会降低文件系统的速度。
- 版本间的空间浪费:即使 Git 存储快照,许多快照之间也只有细微差别。
Git 通过打包文件解决了这两个问题。
打包文件
Git 不会将每个对象都保存为单独的文件,而是定期(在执行git gc 、push 、fetch或clone等操作期间)将多个对象打包在一起:
.git/objects/pack/├── pack-abc123def456.idx (index for fast lookup)└── pack-abc123def456.pack (compressed objects with deltas)- 该.pack文件包含实际的压缩、增量编码数据。
- 该.idx文件是一个索引,可以让 Git 快速定位包中的任何对象。
这大大减少了文件数量,使大型存储库的存储和传输更加高效。
如何节省空间
Git 创建包时,会应用三种主要优化:
- 分组:Git 将相关对象(例如,同一文件的多个版本)聚类,以便有效地压缩它们。
- 增量压缩:Git 不会存储每个版本的完整版本,而是存储一个完整版本,然后存储其他版本的增量(差异)。旧版本可以通过应用这些增量来重建。
- 压缩:打包后的数据会像散装对象一样被压缩(zlib),但现在 Git 通常可以压缩得更好,因为它处理的是更大、结构更复杂的数据集。
对存储库大小的影响
想象一下,一个 1MB 的配置文件被修改了 100 次。
- 如果不进行压缩,Git 会存储许多完整的版本(每个版本都经过压缩,但仍然很大)。最终,历史版本的大小可能达到几十兆字节甚至更大。
- 通过打包,Git 可以存储一个完整版本以及其他 99 个版本的微小增量。如果每次更改只涉及几行代码,那么每次增量可能只有几千字节,因此总增量可能接近几兆字节。
这就是为什么拥有多年历史和数千次提交记录的仓库仍然可以克隆到合理的大小。Git 不会提供每个完整的文件版本,而是提供由打包对象和增量构建的精简版本。
打包的时候
通常情况下,你不需要手动触发打包操作。Git 会自动为你完成:
- git gc显式运行垃圾回收和重新打包
- git push//git fetch通常git clone涉及包装或重新包装以实现高效运输
- 当松散对象的大小超过特定阈值时,Git 还可以自动运行垃圾回收。
你平时很少会想到打包文件,但它们是 Git 能够很好地扩展以及尽管存储了完整的历史记录,但存储库大小仍然可控的重要原因。
要点总结
- Git 是一个内容寻址文件系统。每条数据都以其 SHA-1 哈希值存储。相同的内容,相同的哈希值,只存储一次。
- 三种对象类型至关重要。Blob存储文件内容。Tree 存储目录结构。Commit 存储带有历史链接的快照。
- 这三个区域构成了你的工作流程:工作目录用于编辑,暂存区用于草拟提交,代码仓库用于永久存储。
- 分支只是指针。分支是一个包含提交哈希值的 41 字节文件。创建分支是瞬间完成的。切换分支会重新生成工作目录。
- 合并连接历史记录。尽可能快速合并,分支分叉时进行三向合并。当同一条代码行发生不同变化时,就会发生冲突。
- 打包文件能有效提升 Git 的效率。增量压缩和分组机制使得 Git 能够以极小的空间存储大量的历史记录。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。