



什么是URL参数?URL参数是如何使用的?
URL参数被广泛用于页面变体和活动跟踪,但必须妥善管理以防止可爬取性和重复内容问题。
在本指南中,我们将解释什么是URL参数,它们如何工作,何时有用,以及如何正确管理它们以实现SEO。
我们开始吧。
什么是URL参数?
URL 参数是附加在 URL 末尾的额外信息,告诉网站如何自定义内容、过滤结果或跟踪浏览会话。
这里有一个简单的URL参数示例,用于筛选结果:

URL 参数只是完整 URL 的一部分,通常包括方案、域名、顶级域名和路径。
URL 参数结构
URL 参数出现在问号(?)后面,包含用一个或多个&符号(&)分隔的键值对,这意味着:
- 问号之前的所有内容都是标准URL。
- 所有参数都出现在问号(?)
- 每个参数以键和值表示,中间用等号分隔(类别=鞋子)
- 多个参数用一个&符号分隔(&)
多个URL参数结合起来。你在页面上看到的内容可以根据这些值进行调整。
URL 参数与查询字符串
“URL 参数”和“查询字符串”这两个术语常被交替使用,在大多数语境中这完全没问题。
然而,URL 参数和查询字符串之间存在细微的技术区别。
URL 参数是各个键值对,例如:
category=shoescolor=bluesize=9查询字符串是整个参数字符串,包括问号和和符号:
?category=shoes&color=blue&size=9在你的对话中,可以随意使用“URL 参数”或查询字符串。大多数开发者都明白,他们本质上指的是同一个概念。
URL参数是如何使用的?
URL参数用于增强网站功能和用户体验。
以下是URL参数的一些常见用例:
- 内容过滤和排序:你可以使用URL参数动态过滤或排序内容,而无需用户重新加载整个页面。这对拥有众多产品类别和变体的电商网站尤其有用。或者任何需要帮助用户缩小大量物品集合的网站。
- 个性化:网站可以通过参数定制体验,比如根据用户所在地显示特定地区的页面(?region=us),或用用户偏好的语言(?lang=en)展示内容。对于SEO友好的本地化,有更好的替代方案,我们稍后会详细介绍。
- 分页:URL 参数有助于显示跨多个页面的大量内容(?page=2、?page=3、?page=4 等),以便用户在页面中导航。这对于拥有大量收藏的网站尤其有用,比如博客文章和产品列表。
- 搜索功能:URL 参数也用于网站的搜索功能。当用户提交搜索查询时,查询会附加在 URL(?search=running+shoes)上,使网站能够显示相关的搜索结果。
- 会话管理:一些网站使用 URL 参数来维护会话信息并跟踪用户在多个页面上的活动(?sessionid=xyz123)。然而,Cookie 已经在很大程度上取代了这种做法。
- 活动跟踪与分析:营销人员使用“utm_source=facebook”或“utm_campaign=summer_sale”等参数来评估流量来源,评估活动表现
URL查询参数的主要类型有哪些?
URL 参数大致可分为两类:主动和被动。
主动参数
主动参数直接影响网页的内容或行为。
当URL中出现活跃参数时,网站会利用这些值改变页面显示的内容或功能,从而创造符合用户需求的动态互动体验。
常见的主动参数示例包括:
- 筛选产品列表
- 从分页系列加载特定页面
- 显示区域特定页面
被动参数
被动参数不会改变页面的可见内容,而是在幕后支持追踪用户行为或管理会话等功能。
基本上,被动参数帮助开发者和市场人员收集数据,更好地管理重要流程。
被动参数的典型用途包括:
- 监控交通源
- 识别用户会话
URL中的参数如何影响SEO?
URL参数会对SEO表现和AI可见度产生负面影响,因为它们会导致许多页面内容相似。
URL参数引起的最常见的搜索可见性问题包括:
- 重复内容:参数可能会创建同一页面的多个版本。例如,“?sort=asc”和“?sort=desc”可能会以不同顺序显示相同内容。搜索引擎和人工智能系统可能难以确定优先排序哪个版本,从而降低整体可见度。
- 爬取预算浪费:搜索引擎和AI爬虫在限定时间内只分配一定的时间和资源来爬取网站。如果你的网站生成了许多带有相似内容的URL参数,网站爬虫可能会浪费时间在这些变化上,而不是发现新的、独特的内容。
- 关键词蚕食:多个参数不同的URL通常针对同一组查询。这意味着你的页面在搜索结果中相互竞争。这种内部竞争可能阻碍任何单一页面在传统和人工智能搜索中表现良好。
- 稀释排名信号:当外部和内部链接指向同一页面的多个参数化版本时,链接权益可以分散到这些URL之间,而不是集中在一个规范版本上。这削弱了主页的整体搜索表现潜力。
使用URL参数时的关键考虑
URL参数需要精心规划和管理,因为它们会影响你的搜索可见度。
因此,在使用网站URL参数时,请牢记以下几点:
参数顺序很重要
搜索引擎和人工智能系统可以将参数相同但顺序不同的URL视为独立页面,即使它们显示的内容相同。
例如,“?color=blue&size=9”和“?size=9&color=blue”可能被视为不同的URL。这会造成更多重复内容,影响搜索表现。
实际上,你网站的技术实现会在大多数情况下保持参数顺序一致。对于需要手动创建URL参数的活动,请将团队按正确顺序对齐。
参数导致性能权衡
带参数的URL通常绕过缓存机制,导致服务器获取新内容时加载时间变慢。
如果你的参数对内容没有显著改变,就考虑功能是否值得性能成本。
使用URL参数的5个SEO最佳实践
为了减轻URL参数可能带来的搜索可见性挑战,请遵循以下最佳实践:
1. 添加规范标签
所有参数化的URL都应包含一个规范标签(一种HTML摘要),用来标识不包含参数的页面作为主页。
规范标签的样子如下:
<linkrel="canonical"href="https://www.yourdomain.com/your-main-page"/>规范标签告诉搜索引擎哪些URL应被索引(存储在数据库中)以便排名。这巩固了主页的链接权益,避免重复内容的问题。
此外,随着时间推移,搜索引擎会优先考虑爬取规范页面而非参数化变体,从而提升爬取效率。
清晰的规范信号还能帮助你偏好的页面在AI驱动的搜索系统中显示。
对于具有丰富筛选选项的网站,添加规范标签尤为重要,例如:
- 带有颜色、尺寸、品牌、价格等筛选功能的电商网站。
- 带有位置、价格范围、设施等筛选条件的房地产网站。
- 招聘网站有多种筛选组合,涵盖职位、经验、地点等。
- 任何通过多种参数组合访问类似内容的网站
实现规范标签相对简单。与你的开发者合作,将这行添加到参数化页面的<head>部分以及规范版本中(只需将示例URL替换为你想指定的主页面URL):
<linkrel="canonical"href="https://www.yourdomain.com/your-main-page"/>2. 屏蔽包含Robots.txt参数的URL
在某些情况下,你可能需要通过配置robots.txt文件来防止搜索引擎爬取带有特定参数的URL。
机器人在爬取你的网站前会检查robots.txt文件。而且他们通常会按照指示去避免爬行的页面。请考虑以下情景:
- 你有参数可以生成近乎无限的URL,但几乎没有独特内容
- 你遇到了爬取预算问题,搜索引擎无法抓取所有重要页面,因为有太多带有参数的URL限制
在这些情况下,屏蔽某些参数可以显著提高机器人爬取你网站的效率。并且优先考虑你最重要的内容。
要查看谷歌的爬取活动并识别有问题的参数,请进入谷歌搜索控制台(GSC),进入“设置”。
找到“爬取统计”报告,点击“打开报告”。
滚动到“按文件类型”,点击“HTML”查看谷歌在你网站上的爬取活动。
在“示例”中,寻找可能浪费爬取预算的重复参数化网址。
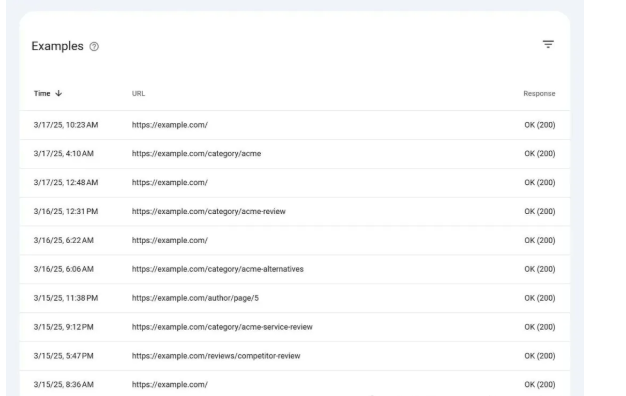
一旦确定了有问题的参数,就在robots.txt文件中屏蔽它们。例如,下面的模块告诉爬虫不要爬取包含“?sort=”的URL,这为更重要的内容节省了爬取预算:
User-agent: *Disallow: /*?sort=3. 避免使用本地化的URL参数
如果你的网站服务不同地区和/或语言的客户,最好避免使用URL参数进行本地化,因为它们不太友好,可能会影响搜索结果。
此外,谷歌明确表示本地化时不应使用URL参数。
最好为每个地区使用专用的网址。这种方法更易用,并为搜索引擎提供更清晰的地理定位信号。
区域特定页面常见的URL结构包括:
- 子目录(例如,example.com/fr/)
- 子域(例如,fr.example.com)
- 独立的国家代码顶级域名(例如,example.co.fr)
4. 使用一致的内部链接
你自己网站上的内部链接应指向每个页面的干净、规范版本——而非参数化的变体。
持续链接到规范页面可以巩固链接价值,并向搜索引擎和人工智能系统发出明确的信号,告诉他们应该优先考虑哪个页面。
5. 将参数化的URL排除在审计中
排除参数化URL进行SEO审计,可以让审计聚焦于你网站的核心内容。
使用 Semrush 的免费 SEO 检查工具 Site Audit 时,你可以配置该工具排除参数化 URL 进行爬取。
打开Site Audit,输入您的域名,然后点击“开始审计”。
在设置向导中,选择“URL 参数规则”,列出你想排除的爬取参数。例如,在文本框中输入“page”会排除诸如“?page=1”、“?page=2”和“?page=3”这样的分页参数。
列出你想忽略的参数后,点击“开始审计”。
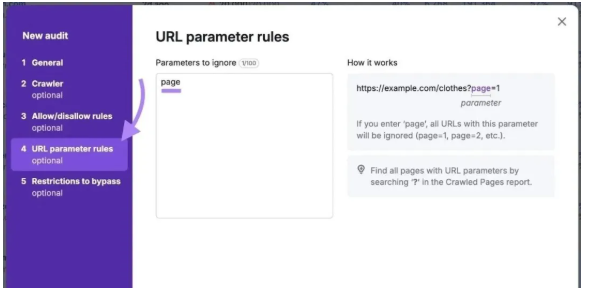
爬取完成后,Site Audit 会生成一份报告,显示您网站的整体技术健康状况。
你还会看到一系列影响你重要内容的问题。
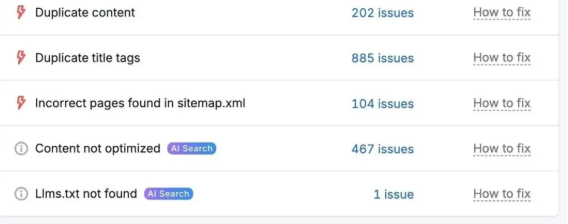
审查Site Audit的发现,重点实施最有可能产生最大影响的修复方案。一般来说,优先处理错误。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。