



多模态embedding模型的分类有哪些?
“ 多模态嵌入模型有模态融合和单独嵌入两种不同的方式。”
在多模态RAG中,由于多模态数据的复杂性,基于文本的Embedding模型已经无法满足需求,因此就需要使用专门针对多模态数据的多模态嵌入模型。
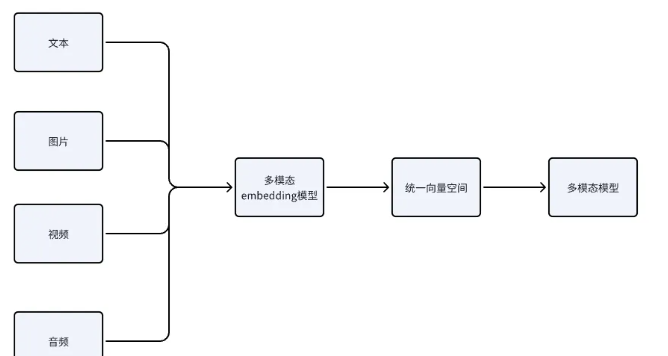
多模态嵌入模型的原理是通过对多种不同模态的数据,通过模态融合的方式,映射到统一向量空间,然后就可以同时支持多种模态数据的检索。
虽然从使用者的角度来看,多模态嵌入模型和普通的文本嵌入模型好像没什么区别;但是作者在使用多模态嵌入模型时发现一个小问题,就是多模态嵌入模型也存在不同的类型,其功能点也不尽相同。
所以,今天我们就简单讨论和记录一下关于多模态嵌入模型的问题。
多模态嵌入模型
嵌入模型可以说是大模型应用中,自然语言和大模型之间的桥梁,如下图所示:

嵌入模型(embedding模型)的出现是为了解决人与模型对话的问题,在现今基于神经网络的大模型技术中,模型的主要数据载体是向量,因此就需要一种技术把人类的语言转换成模型能够看懂的“语言”,而这个工具就是嵌入模型。
用技术的语言来描述嵌入模型,嵌入模型(Embedding Models)是机器学习和自然语言处理中的关键技术,用于将高维、非结构化数据(如文本、图像)转化为低维向量表示,从而实现语义理解和高效检索。
我们都知道大模型是在自然语言处理的基础上发展起来的,因此刚开始嵌入模型都是针对自然语言进行处理;但随着技术的发展,多模态模型的崛起,怎么打通多模态数据与大模型之间的桥梁就成了一个问题,这时借助于文本嵌入模型的思想,把不同模态的数据通过多模态嵌入模型映射到统一向量空间,就可以实现多模态的检索。
而多模态嵌入模型的实现原理是,通过对不同模态的数据进行模态融合,其中涉及到多模态数据表示,跨模态对齐等技术;本质上来说,也是使用神经网络或者机器学习算法,提取不同模态数据的特征,并通过某种算法,变换成统一的低维向量,这个过程就是转换统一向量空间的过程。
但是,多模态RAG虽然在理论上行得通,但在实际应用场景中使用的比较少,原因主要在于成本太高,流程太复杂,效果又不太好;而业内所谓的多模态RAG主流的处理流程,还是对多模态数据进行文本提取,通过文本的形式进行实现语义检索,而不是直接用多模态融合的方式进行检索。
在实际的操作中,多模态嵌入模型分为两个类别,一种是使用多模态融合技术,同时输入多种不同模态(目前大部分只支持两种模态)的数据,然后转换成低维向量,之后就可以使用一种模态的数据进行检索。
另一种类别是,多模态嵌入模型支持把不同模态的数据,分别进行向量转换,如文本数据转换成文本向量,图片数据转换成图片向量,然后在检索的时候分别进行检索,最后再进行组合。
而以上几点也是目前多模态RAG实现的主要思路,但由于技术还不够成熟,多模态RAG还存在各种各样的问题,其应用范围并不是很广;主要应用场景有,文搜图和图搜图,这应该算是电商领域比较常见的应用了。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。