



异构超级 SoC 是什么?为什么能统治未来数据中心
未来 5 年是全球 AI 芯片创新的时代,也是创业最好的时代,一定要跟住了...
AIsoc创新就是一切为了省电...
未来的产业模式就 3 层:能源--基础设施(AISOC)--智能体应用
在过去很长一段时间里,半导体行业存在着泾渭分明的界限:做CPU的公司(如Intel、AMD、Arm)专注于通用计算,做AI芯片/GPU的公司(如NVIDIA、各类初创AI芯片公司)专注于并行加速。
随着大模型时代的算力饥渴和访存墙(Memory Wall)日益严峻,这条界限正在彻底消亡。
未来,不再有独立的AI芯片公司,也不再有独立的CPU公司。
研发AI芯片的企业必须向上突围做CPU(如NVIDIA的Grace),研发CPU的企业必然向下整合AI芯片(如AMD的MI300A)。而对于互联网云厂商(CSP)而言,最核心的趋势是“强强联合”——将顶级的CPU IP与自研的AI算力进行深度物理缝合,最终走向“一芯万物”(一个超级SoC/SiP搞定所有)的终极形态。
谷歌被曝光的第九代TPU架构——v9ax "Humufish",正是这一行业巨变的最佳缩影。
从“斑马鱼”到“腐殖鱼”:走向超级异构SoC
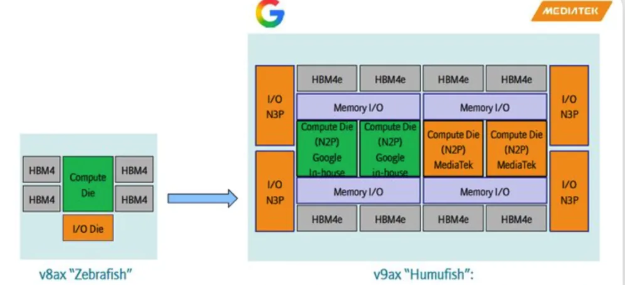
曝光的架构演进图,我们可以清晰地看到算力中心芯片在物理形态上的跨越式迭代:
前代架构(v8ax "Zebrafish"):采用的是相对传统的CoWoS-S(硅中介层)2.5D封装方案。它的结构是一个典型的“独立AI加速器”形态,中心是一颗单片(Monolithic)的Compute Die(计算核心),下方是I/O Die,两侧挂载4颗HBM4内存。此时,它还需要通过PCIe等总线与外部的独立Host CPU进行通信。
第九代架构(v9ax "Humufish"):这是一次暴风骤雨般的架构重构。它摒弃了单片设计,走向了极高集成度的基于Chiplet的异构超级SoC/SiP。
为什么不存在独立的CPU或AI芯片了?
“Humufish”的合封方案深刻地揭示了数据中心底层的演进逻辑:
1. 消除“数据搬运税”(Data Movement Tax)
在传统的“独立CPU + 独立AI加速卡”架构中,数据需要在CPU内存、系统总线(PCIe)、GPU/TPU HBM之间来回搬运。对于动辄万亿参数的大模型推理和训练,PCIe的带宽瓶颈使得数据搬运产生的功耗和延迟远大于计算本身。将CPU和AI芯片合封在同一个基板上,共享统一的内存空间(HBM4e),实现了真正的片上高带宽低延迟互联,从根本上打破了访存瓶颈。
2. 强强联合的必然性
谷歌作为AI算法和架构的先驱,拥有无与伦比的TPU设计能力,但在高性能通用ARM CPU的底层物理实现、IP积累上,并不如传统的SoC巨头。联发科(MediaTek)则拥有深厚的ARM CPU定制设计能力和先进制程SoC的整合经验。
这种“云厂商(自研AI芯) + 传统SoC巨头(提供定制CPU与整合服务)”的强强联合,成为了当前最优的商业与技术双赢模式。谷歌不需要从头造CPU的轮子,联发科也成功杀入顶级AI算力中心的腹地。
3. “一个芯片搞定所有”的Super SoC时代
未来算力中心的最小计算单元将不再是一台由主板、CPU、数张AI加速卡拼凑而成的服务器,而是一颗颗巨大的Super SoC (System in Package)。
在这颗“芯片”内,不仅有负责控制逻辑和数据预处理的CPU,有负责矩阵运算的AI Die,有海量的HBM4e内存,甚至还会集成负责集群互联的硅光网络I/O芯片。这颗芯片就是一个完整的计算节点。
从谷歌与联发科的合封,到NVIDIA Grace Hopper/Blackwell的推广,整个AI芯片行业正在经历一场由“分”到“合”的轮回。
对于算力中心从业者而言,这意味着我们需要重新审视未来的基础设施架构设计。
传统的以PCIe为核心的服务器拓扑将被重构,单节点的算力密度、散热功耗(TDP)将迎来指数级跃升(如Humufish这种级别的芯片,其散热设计将是极大的挑战)。
AI芯片与CPU的边界已然消散,一个由高度整合的异构超级芯片统治数据中心的新纪元,已经随着“Humufish”的到来拉开了帷幕。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。