



AI
用哪个大模型写代码更好?大模型代码编程能力评测排行榜
陈易
2026-02-25
9小时前
一、这份排行榜到底评测了什么?
榜单中包含三类关键指标:
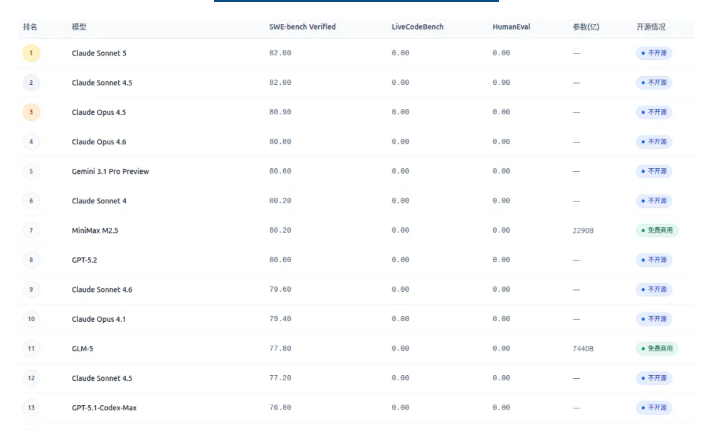
- • SWE-bench Verified:当前最权威的真实软件工程评测,基于真实项目 Issue,让模型修复 Bug 或实现功能。这是真实环境下的能力,而不是“做几道算法题”那么简单。
- • LiveCodeBench:更偏向真实编程场景的互动式评测,但目前大部分模型的该项能力仍未披露。
- • HumanEval:较经典的编程能力测试,但越来越被认为“对大模型过于简单”。
这意味着:这份榜单真正看重的是大模型在真实开发场景中的代码能力,而不是算法小题目的表现。
二、从榜单看行业趋势:闭源最强,但中国开源力量正在上升
1. 闭源模型霸榜,但性能差距正在缩小
榜单前 10 名几乎被 Anthropic Claude 系列 + Google Gemini + OpenAI GPT 系列霸榜,SWE-bench Verified 得分均接近或超过 80 分。
这说明闭源模型仍然在多模态理解、推理链路优化、代码安全约束等方面走在行业最前列。
但值得注意的是:
差距已经不是“碾压级”,更多是“领先半代”。
三、中国模型亮点:开源 + 免费商用正在形成力量对冲
虽然闭源模型占据榜单前列,但国产模型表现令人惊喜:
1. MiniMax M2.5(排名第 7)
- • SWE-bench 达到 80.20,进入国际顶尖行列
- • 参数量 2290B(2.29T),免费商用
这意味着它不仅性能强,而且企业可以直接落地,无需昂贵授权。
2. GLM-5(排名第 11)
- • SWE-bench 得到 77.80
- • 7440B 参数,同样免费商用
- • 优势在于推理链路稳定、一致性强,非常适合 ToB 场景
3. Kimi K2.5(排名第 14)
- • SWE-bench 得分略低,但 LiveCodeBench 达到 85.00,压过所有闭源模型
- • 参数量高达 1T(10000B)
尤其 Kimi 在 LiveCodeBench 的表现说明了一个趋势:国产模型在真实长期上下文、多轮代码任务中具有天然优势。
这对企业特别重要,因为真正的软件工程从来不是“一次命中”,而是“反复迭代 + 修补”。
四、我看到的趋势与价值
1. 大模型正在从“能写代码”迈向“能开发软件”
SWE-bench 的本质不是考推理,而是:
- • 能否理解业务意图
- • 能否分析真实代码库
- • 能否修改正确文件
- • 能否通过真实测试用例
这意味着模型能否融入企业的 DevOps 体系,而不仅仅是当“代码生成器”。
未来 1–2 年,具备 SWE-bench 80+ 能力的大模型,将开始扮演以下角色:
- • 自动找 Bug
- • 自动改 Bug
- • 自动生成单元测试
- • 协助代码重构
- • 自动生成 API 文档
- • 自动评审 MR/PR
AI = 新时代的“代码自动化工程师”
2. 开源大模型的崛起将改变技术选型成本
对于企业 IT 架构师来说,有三个关键问题:
- • 许可证能否商用?
- • 模型能否私有化部署?
- • 成本能否可控?
在这点上,MiniMax、GLM、Qwen 都提供了现实可行的路径。
这代表一个重大趋势:
未来大型企业的 AI 编程体系不可能只依赖闭源模型,而是混合式架构:闭源 + 开源 + 本地推理。
五、总结:AI 程序员时代正式到来
从这份排行榜中,我看到的不只是数据,而是未来 10 年软件工程的巨大变革:
- • 软件工程将从“人写代码”迁移到“人机协同写代码”
- • 代码库将由人维护,逐渐变为「由 AI 维护」
- • 新时代软件架构师的核心能力,将从“写代码”转向“ orchestrate AI 工程能力 」
最终,我们要学会:
不是让 AI 写更多代码,而是让 AI 写对代码。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。
分享文章