



什么是LLM? LLM的工作原理
大语言模型是当前人工智能革命的核心驱动力。它不仅仅是“会聊天的AI”,而是一个在理解、生成和推理人类语言方面表现卓越的复杂系统。
一、 什么是LLM?定义与演变
1. 核心定义:LLM是一种基于海量文本数据训练的深度神经网络模型,其核心目标是理解和生成人类语言。LLM通常指参数规模巨大(十亿乃至万亿级别)的模型,但“大”是相对的,其核心能力在于对语言的深度建模。
2. 两类主要模型:
• 仅编码器模型:如BERT。主要用于理解与表示文本,擅长文本分类、情感分析、语义相似度计算等任务。它通过双向注意力理解上下文,但本身不生成新文本。
• 仅解码器模型:如GPT系列。主要用于生成文本,通过自回归的方式,根据已有上下文预测下一个词元,从而实现对话、创作、代码生成等能力。以ChatGPT为代表的对话模型正是此类模型经过指令微调和对齐后的产物。
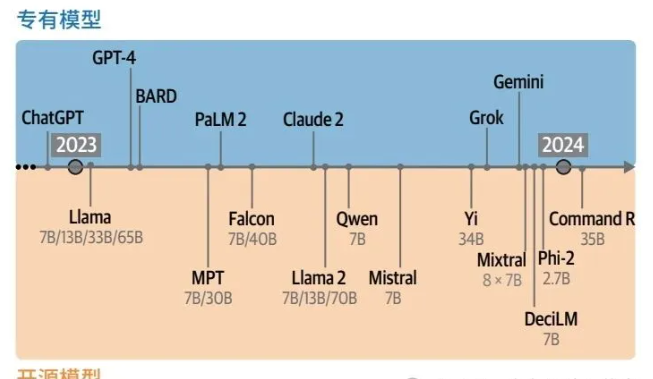
3. “生成式AI元年”:2023年因ChatGPT的爆火被称为生成式AI元年。这不仅是技术的突破,也标志着开源与专有模型生态的繁荣(如Llama、Mistral等),以及新架构(如Mamba)的探索。
二、 LLM的工作原理:从文本到智能
LLM处理文本的流程是一个精密的系统工程,其核心在于 “词元化” 和 “注意力机制”。
1. 分词:模型并不直接理解单词。首先,分词器将输入文本拆分成更小的单位——词元。词元可以是单词、子词、字符甚至字节。例如,“apologizing”可能被拆分为 “apolog” 和 “izing” 两个词元。分词方式(如BPE、WordPiece)和词表大小直接影响模型处理不同语言、代码和特殊符号的能力。
2. 嵌入:每个词元被转换为一个高维数值向量,即词元嵌入。这些初始嵌入如同“字典”,存储了词元的静态语义。
3. Transformer的核心:注意力机制与上下文编码
• LLM的核心是 Transformer架构。它摒弃了RNN的顺序处理缺陷,支持并行训练,极大地提升了效率。
• 自注意力机制是Transformer的灵魂。它允许模型在处理一个词元时,动态地关注并整合序列中所有其他相关词元的信息。例如,在句子“The dog chased the squirrel because it was fast.”中,为了确定“it”指代“dog”还是“squirrel”,模型需要通过注意力机制将“squirrel”的上下文信息赋予“it”。
• 多头注意力:使用多个独立的注意力头,让模型能够同时关注不同类型的依赖关系(如语法、语义、指代)。
• 位置编码:由于注意力机制本身不考虑顺序,需要额外加入位置信息,让模型理解词元的顺序。
4. 前向传播与生成:词元嵌入序列,加上位置信息,输入到由多层 Transformer块堆叠而成的网络中。每个块包含自注意力层和前馈神经网络层。前馈层存储了大量从训练数据中学到的知识和模式。
5. 自回归生成:生成式LLM通过循环进行预测:输入提示词→生成第一个词元→将生成的词元追加到输入中→再次预测下一个词元……如此循环,直到生成完整响应。此过程可借助键值缓存来加速。
三、 LLM的训练范式:三步走策略
训练一个强大的LLM并非一蹴而就,通常遵循多阶段范式:
1. 预训练:在海量无标注文本(如网页、书籍)上进行“下一个词元预测”训练。这是计算和资源消耗最大的阶段,目的是让模型学习通用的语言规律、知识和世界模式,形成“基座模型”。
2. 监督微调:使用高质量的指令-回答对数据对基座模型进行微调,使其学会遵循人类指令、理解任务格式,成为“指令模型”。
3. 偏好对齐:基于人类反馈的强化学习等技术,让模型的输出更符合人类的价值观、安全性和帮助性偏好,从而成为如ChatGPT般安全、有用的“对话模型”。
四、 LLM的主要应用
LLM的能力使其适用于极其广泛的任务,重点介绍了以下几类:
1. 文本分类与聚类:利用表示模型(如BERT)或生成模型的零样本、少样本能力,进行情感分析、主题分类和文档聚类。
2. 提示工程与高级文本生成:通过精心设计提示词(指令、上下文、示例、输出格式等),可以解锁模型的复杂推理能力,如思维链、自洽性、思维树等,用于解决数学、逻辑问题。
3. 语义搜索与RAG:
• 语义搜索:使用嵌入模型将查询和文档转换为向量,通过计算向量相似度找到语义最相关的结果,超越了传统关键词匹配。
• 检索增强生成:将搜索与生成结合。先检索相关知识库,再将检索到的信息作为上下文提供给LLM,让其生成基于事实的答案,有效减少幻觉,实现“与数据对话”。
4. 多模态扩展:通过连接视觉编码器(如ViT)和LLM(如BLIP-2架构),LLM获得了“看”的能力,可以实现图像描述、视觉问答、多模态对话等。
5. 智能体与工具使用:通过ReAct等框架,LLM可以学会调用外部工具(如计算器、搜索API),具备自主规划、行动和观察的能力,从而解决更复杂的现实世界任务。
五、 开发和使用负责任的LLM
因LLM的巨大社会影响力带来的责任:
• 偏见与公平:训练数据中的社会偏见可能被模型学习并放大。
• 透明度与问责:需明确AI与人类的交互边界。
• 有害内容与幻觉:模型可能生成虚假、误导或不安全的信息。
• 知识产权与监管:生成内容的版权归属,以及全球范围内(如欧盟AI法案)日益完善的监管框架。
总结
总而言之,大语言模型是一个由Transformer架构驱动,通过海量数据预训练和多阶段微调获得的复杂系统。其核心能力源于注意力机制对上下文的动态建模。从基础的文本理解与生成,到高级的语义搜索、RAG、多模态交互和智能体行为,LLM正在重塑我们与信息和技术交互的方式。然而,在拥抱其潜力的同时,我们也必须正视并应对其在伦理、安全和社会影响方面的挑战。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。