



AI大模型车载软件平台架构及关键技术
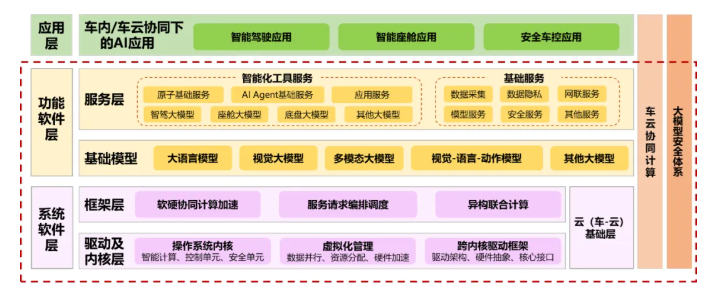
AI 大模型车载软件平台参考架构包含系统软件层、功能软件层、车云协同计算层和安全体系(如图 1 所示)。平台向下通过多模态感知融合接口,实现与各类传感器阵列、通信及控制系统深度集成;向上提供面向智能驾驶、智能座舱、智能底盘和大模型共性功能等高实时高安全计算平台,实现毫秒级任务响应,为整车全域 AI 化提供核心支撑。
异构跨芯片计算硬件负责感知各类部署硬件的计算特性,对 AI 大模型进行自适应切分,支持异构并行化推理,关注车载AI 大模型芯片或硬件平台的硬件架构和智能计算性能。
AI 大模型车载软件平台采用纵向分层(包含系统软件层和功能软件层)、横向分区式架构,支撑 AI 大模型智能车载软件的功能实现和安全可靠运行。
系统软件层纵向分为驱动及内核层、框架层。通过标准的内核接口(包括大模型智能计算内核、大模型控制单元内核和大模型安全处理内核等)向上层提供服务,实现与上层软件的解耦;通过跨内核驱动框架(包括驱动架构、硬件抽象和核心接口)实现与硬件平台的解耦,与操作系统内核的解耦。框架层提供 AI 大模型下的计算新框架,如跨芯片计算、软硬优化、大模型计算部署等框架。
功能软件层纵向分为基础模型和服务层。基础模型层借助标准的应用软件接口,为上层应用软件的开发与集成提供有力支持,实现大模型车载软件平台与应用软件解耦。服务层根据各类智能驾驶、智能座舱及车载智能功能的共性及特性需求,定义并实现底层的基础服务组件和专用的智能化工具服务。
车云协同计算层提供 AI 大模型下,车载计算与云(或边)协同计算框架,如支持智能驾驶的快(车端)慢(云端)的车云一体、智能座舱大模型的模型端云协同计算等。
大模型安全体系聚焦模型本体安全、数据资产安全、信息内容安全、运行时安全、供应链安全,采用数据全生命周期加密与脱敏强化、对抗性攻击主动防御等技术保障安全。
架构特征
- 分层解耦
AI 大模型车载软件平台采用分层设计理念,通过“驱动及内核层-框架层-模型层-服务层-应用层”的解耦体系,实现全栈模块化开发。
- 跨域共用
区别于传统车载软件平台“烟囱式”架构,该平台通过 AI 大模型的跨模态融合能力,打通动力域、底盘域、座舱域与智驾域等全域的数据壁垒,实现跨域 AI 大模型平台共用,支撑智能汽车全域 AI 的发展趋势。
- 安全可靠
该平台满足车载软件平台对高实时、高可靠和高安全的要求,构建包含全栈安全产品及全面安全体系,将 AI 大模型功能安全、信息安全和数据安全等融入框架设计中。
AI 推理芯片
AI 大模型相比于传统神经网络模型,参数量和计算量都有数量级的提升,对车载芯片设计提出了挑战。同时芯片工艺制程演进放缓,单纯采用先进工艺难以满足 AI 大模型的车载应用需求,需要从底层微架构到顶层系统设计等多种技术。本章节从核心内部架构、芯片级架构以及系统级架构三个层次(如图2所示),介绍 AI 推理芯片的若干关键技术、及对应软件支撑。
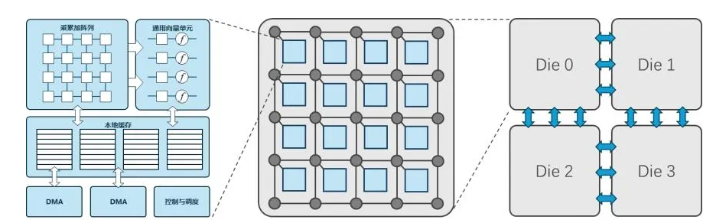
图2 AI 大模型车载芯片的三个技术层次
- 核心内部架构
神经网络处理器设计关键,是如何在有限面积、功耗、带宽限制下提升处理器核心的性能,其依赖的是软硬件协同设计。
模型压缩的核心是在可接受的模型性能损失范围内,降低模型的表示精度或参数量,从而达到加速模型处理的目的。采用模型压缩技术,通过特定的模型压缩方式,结合与之适配的硬件架构,可以大幅提升核心性能。
(1)混合精度量化技术
模型量化技术是主流的模型压缩技术之一,目前已经广泛应用于各种神经网络处理器中。神经网络算法在训练过程中通常采用单精度浮点数进行前向推理计算和反向传播优化。模型部署时,更低精度的浮点数或整数进行计算对模型的计算结果影响不大。因此硬件可以采用更小规模的缓存和计算单元,从而在相同的功耗和面积限制下实现更高的性能和能效。如Deepseek 在其最新的模型中部分采用了该精度进行模型训练和推理;对于成本、功耗受限的车载平台,定制化的 AI 处理器应直接支持上述精度以降低芯片的面积和功耗。
采用更低位宽的数值表示必然也会带来更大的量化误差,通过引入分组量化的概念可以缓解这个问题。最基本的量化方法中,一层的权重、输入和输出分别被赋予一个统一的量化系数。先进的量化技术针对不同的模型和数据类型,采用不同的量化分组方式,定制化架构则可以直接利用量化后的数据计算,充分发挥量化带来的优势。
(2)模型稀疏化支持
传统的模型剪枝方法主要关注在减少模型参数或计算中间层的激活值,但是在峰值性能降低的同时,也难以达到和剪枝比例对等的加速比。结构化剪枝则解决了上述问题,比如以块为单位进行剪枝,以及在固定大小的数据块内采用固定比例的方式进行剪枝等。考虑到 AI 大模型对内存的高要求,支持细粒度的结构化剪枝预计是未来车载芯片的重要特性。
对于语言类模型,其中的 Attention计算随着输入 token的长度成平方复杂度增长,可以通过在算法层面引入静态或动态注意力机制来降低计算复杂度。其中,动态注意力机制则需要底层硬件支持排序或 topk 等特殊算子,支持 AI 大模型的车载芯片需要在底层架构上支持动态稀疏特性。
- 芯片级架构
随着 AI 大模型引入,以低延时为核心目标的高性能单核心的设计理念不再适用,分布式的多核心架构由此而生。AI 算法的多核心并行计算包括 Batch 并行、流水线并行、层内并行等,在不同的应用场景下需要不同的并行模式。高效的芯片缓存组织结构和片上网络结构是车载芯片支持 AI 大模型的重要技术演进方向。
- 系统级架构
大语言模型以及生成式模型的参数量、单次推理的计算量,相对于传统模型扩大了 1-2 个数量级,对 AI 推理芯片的算力,以及芯片整体规格、良品率、成本以及性能有着较高要求。在面向 AI 大模型的车载芯片系统级架构设计中,需要引入多芯粒等一系列新技术,在实现相同规格的芯片时提高良品率。对于成本敏感的车载芯片而言,多芯粒技术是支持 AI 大模型的关键。
因此在面向 AI 大模型的车载芯片设计中,需要引入一系列新技术。随着单一芯粒的面积扩大,相同尺寸的晶圆上实际可用的面积缩减,同时芯粒的良品率也会急剧下降。而解决大规模芯片制造的一项关键技术就是多芯粒技术。多芯粒技术通过芯粒与芯粒之间短距离的高速互联,使得一颗芯片的封装内可以同时集成多个芯粒,在实现相同规格的芯片时获得更高的良品率。
而这种高速互联技术也可以从一个颗芯片内部拓展到多个独立的芯片之间,允许多颗芯片进一步组成更大的系统。对于成本敏感的车载芯片而言,多芯粒技术是支持 AI 大模型的关键。多芯粒技术一方面依赖于芯粒内部的高速互联接口,另一方面依赖于支持高速互联的封装技术。按照封装技术的不同可以划分为 2D 封装、2.5D 封装以及 3D 封装。
AI 大模型安全处理单元
构建稳固且高效的车载 AI 芯片安全架构,成为确保车辆安全运行、保护用户隐私的关键所在。
- AI 大模型芯片的功能安全架构
大模型芯片作为 AI 大模型车载软件平台的基座,如果没有对故障进行有效的监测和控制,会影响到整体系统的功能安全性。硬件设计的安全机制包括冗余设计、监测电路设计、数据校验等,也可以采用一些离线安全机制来检测硬件故障。支持AI 大模型的复杂 SoC,需要相对独立的、高功能安全等级的MCU 子系统作为“安全岛”。它主要负责全芯片的故障检测机制的管理和控制、故障的收集和上报以及故障的处理等,如采取功能降级、重新启动等措施,使系统进入到安全状态。
- AI 大模型芯片的信息安全架构
来自系统外部的攻击业界归结为信息安全问题,国际上有ISO/SAE 21434 标准、UNECE R155 法规等,我国已发布汽车整车信息安全技术要求 GB 44495。芯片往往需要具备安全启动、加密与解密、数字签名、访问控制、物理安全防护等功能。
AI大模型车载软件平台关键技术
- 大模型车载软件操作系统内核
面对智能网联复杂场景,大模型车载软件操作系统内核体系通过大模型智能计算内核、控制单元内核和安全处理内核的协同工作,为车辆提供坚实基础。
- 大模型智能计算内核
主要负责为大模型在车端运行提供强大的计算支持,服务于智能驾驶、智能座舱等典型应用场景。它通过高效的数据处理能力和智能推理能力,使得汽车能够在复杂的环境中自主决策,提升人机交互体验。
- 计算能力支撑智能驾驶
车辆需要实时处理摄像头、毫米波雷达、激光雷达等大量传感器数据,以实现环境感知、目标识别。智能计算内核通过深度学习模型与并行计算技术,高效解析上述数据,为智能驾驶决策提供精准支持。还具备自适应优化能力,能够动态调整计算资源,提高推理效率。
- 提升智能座舱交互体验
智能计算内核支持多模态数据融合,为语音、视觉、手势等交互提供更自然体验;处理驾乘人员语音指令,结合面部表情、眼动追踪、行为习惯等数据,提供个性化服务。
大模型智能计算内核采用先进的计算优化技术,以提高计算效率并降低资源消耗:
- 并行计算:利用多核处理架构,将计算任务分解并分配到多个核心执行,提高数据处理速度。
- 缓存优化:通过 LLM 内核进行缓存管理,减少重复计算,加速推理过程。
- 自适应计算调度:根据车载环境动态调整计算任务的优先级,确保计算性能与能耗之间的平衡。
为了保障计算过程的安全性和可靠性,大模型智能计算内核集成了智能安全防护机制:
- 自主安全检测:利用 AI 监控计算任务,识别潜在的异常或攻击,并自动调整防御策略。
- 智能故障恢复:计算出现故障时,系统能够自主诊断问题并采取相应修复措施。
大模型控制单元内核
专注于对车辆各类控制功能的管理和执行,确保车辆的稳定运行和精准控制。动力系统中,大模型控制单元内核根据车辆实时运行数据,分析和优化动力系统的控制策略。在不同驾驶模式下智能调整动力输出,满足驾驶员对舒适性或动力性的不同需求。底盘控制系统中,实现对悬挂、转向、制动等系统的精确控制,比如实时调整悬挂的硬度和高度,提高驾驶舒适性;可以根据车速、转向角度、制动力分配等信息,控制提高转向精准度和安全制动。
大模型安全处理内核
主要负责处理与车辆安全相关的任务,包括信息安全和功能安全,是保障车辆安全运行的核心。信息安全方面,大模型安全处理内核采用加密、认证、防火墙等多种安全技术,保护车辆的通信数据和系统安全。例如对车辆与外部网络之间传输的数据进行加密,防止数据被窃取或篡改。功能安全方面,大模型安全处理内核通过风险评估、冗余设计和故障检测等机制,确保系统在出现故障时仍能安全运行。还与其他内核紧密协作,共同保障车辆整体安全。例如智能驾驶场景中,当大模型智能计算内核做出决策后,大模型安全处理内核会对决策指令进行安全验证,确保指令的安全性和可靠性,然后再将其传递给大模型控制单元内核执行。
虚拟化管理
智能网联汽车 AI 具备以下特点:
一是智能业务异构。车载AI 大模型会覆盖到智能驾驶及控制、智能交互、智能运维等多种智能化业务,对于实时性、确定性、安全性的要求不一样;算力也需求不一样,有些是比较恒定的,有些是动态变化的。如何使这些业务有序部署、控制干扰,最大化 AI 能效比,尤为重要。
二是智能算力异构。不同于云端 AI 的同构算力,当前车端 AI 是异构算力,不同车型有不同芯片,同一车型的座舱域、智驾域等控制器 AI 芯片也不同,向 AI 大模型部署提出挑战。AI 虚拟化如单系统 AI 算力虚拟化、分布式 AI 虚拟化、AI 模型虚拟机,能解决上述问题。
跨内核驱动框架
跨内核驱动框架旨在构建一个通用的软件架构,以支持不同类型的内核(宏内核、微内核、混合内核),并实现对多样化硬件环境的适配。该框架通过模块化设计和分层架构,提供稳定、高效、可扩展的驱动支持,确保大模型在各类车载计算环境中的稳定运行。
大模型驱动架构构建:支持宏内核、微内核、混合内核架构。
跨内核驱动框架在不同内核架构下适配至关重要。宏内核、微内核和混合内核各具特点,在汽车软件系统中被广泛应用。针对不同内核架构,跨内核驱动框架采用模块化和分层设计,以实现灵活适配。
模块化设计:大模型推理模块、内核交互模块等被封装为独立模块,以便适配不同内核环境。
分层架构:包括硬件抽象层(HAL)、内核适配层和大模型服务层,确保跨内核的兼容性与拓展性。宏内核环境下,充分利用宏内核的丰富生态,如文件系统、网络通信和多任务处理能力,加速大模型的推理和数据处理。微内核架构下,着重于实时性和系统资源管理,确保大模型能在受限资源条件下高效运行。混合内核架构中,跨内核驱动框架需协调不同内核机制,优化计算任务分配,提高整体性能。
大模型推理硬件抽象:实现对不同硬件的抽象和封装。
汽车硬件环境的多样性使得大模型推理需要适应不同的计算平台,包括 CPU、GPU、NPU,以及各种传感器和执行器。跨内核驱动框架通过硬件抽象层(HAL)解决这一问题,使得大模型能无缝适配不同的硬件配置。HAL 主要功能包括:
- 传感器数据抽象。支持摄像头、毫米波雷达、激光雷达等多种传感器,提供统一的数据采集和处理接口。
- 计算资源管理。对CPU、GPU、NPU进行统一抽象,动态分配计算资源,提高推理效率。
- 执行器适配。将车辆控制功能抽象成标准接口,大模型可通过
HAL 控制底层执行器,实现精准操控。
- 硬件扩展性。HAL 具备良好的可扩展性,当新硬件加入
时,只需增加相应的驱动支持,即可实现快速适配。
大模型核心接口设计:定义跨内核的通用驱动接口。
为了在不同内核环境下保持大模型的稳定性和可移植性,跨内核驱动框架设计了一套通用的核心接口,包括文件操作接口、中断处理接口和内存管理接口。
- 文件操作接口。统一管理大模型的文件资源,支持文件打开、关闭、读写等基本操作。支持大规模训练数据的存取,提高大模型数据读写效率。
- 中断处理接口。负责管理传感器事件、外部设备通信等中断,实现快速响应。统一提供中断注册、注销、触发等功能,确保大模型对紧急事件的快速处理。
- 内存管理接口。负责分配和释放大模型运行所需的内存资源,避免内存泄漏和碎片化,提高系统内存利用率。保障内存隔离,防止进程间非法访问,提高系统稳定性。
框架层
针对车载环境资源受限、实时性严苛及多模态场景需求,构建软硬协同计算加速、服务请求编排调度、异构跨芯片计算等框架体系,支撑 AI 大模型高效部署和安全运行。
- 软硬协同计算加速
软硬协同计算加速框架聚焦 AI 大模型推理的单点计算优化,通过分层量化压缩、动态混合精度调度、显存智能复用、硬件定制算子优化及计算图自动融合等核心技术突破车载算力瓶颈,实现单卡百亿级模型的实时推理。
(1)量化压缩:在车载资源受限环境下,AI 大模型显存占用高、计算开销大,难以满足实时性需求。通过分层量化策略,包括静态量化(Static Quantization)和动态量化(DynamicQuantization),结合 W4A16、W8A8等配置,利用 LMDeploy的TurboMind 引擎和 NVIDIA TensorRT-LLM 等自动量化校准工具,显著降低显存占用和计算开销。
(2)混合精度计算:车载硬件算力有限,传统 FP32 计算效率低、功耗高,难以满足高吞吐需求。通过动态精度切换(如 FP16/BF16 训练、FP8 推理)和自动混合精度(AMP)调度,最大化算力利用率。针对车载芯片定制混合精度算子库(如 TensorRT-LLM 的 FP8 引擎),保证模型精度,同时显著提升计算效率,降低功耗,满足车载环境对能效比的严苛要求。
(3)显存复用:长上下文场景下 KV Cache 显存占用高,传 统 静 态 分 配 导 致 资 源 浪 费 。 引 入 PagedAttention 和RadixAttention 等技术,将 KV Cache 分页管理并缓存公共前缀,支持跨请求显存共享。结合 CUDA Unified Memory 和 Zero Inference 动态卸载冷数据至 CPU 内存,实现显存利用率提升。
(4)算子优化:车载硬件特性多样,通用算子性能不足,难以充分发挥硬件算力。针对 GPU 和 NPU 分别定制高性能算子,如基于 CUDA/Triton 的 FlashAttention-2、Grouped GEMM,以及高通 Hexagon NPU 的 INT8 稀疏计算内核。通过内核融合技术减少全局内存访问次数,提升 GPU SM 利用率。
(5)计算图融合优化:传统计算图存在冗余节点和访存开销,导致推理效率低下。采用非侵入式融合引擎(如 TVM Auto-Scheduler、ONNX Runtime Graph Optimizer),自动搜索最优算子融合策略,减少计算图节点,提升推理效率。
服务请求编排调度
针对车载多任务高并发场景,采用阶段解耦计算、显存弹性管理、热冷神经元分层部署、模型动态加载及 LoRA 批处理优化等核心策略,实现多任务高并发下的资源最优分配。
(1)Prefill 与 Decoding 阶段解耦与协同优化:生成式模型的计算需求可以分为两个阶段:Prefill 和 Decoding。Prefill 阶段是计算密集型任务,而 Decoding 阶段则是访存密集型任务。将Prefill 和 Decoding 阶段部署于独立资源池,资源池之间需要配置高速的网络互联,确保 Prefill 与 Decoding 阶段 KV Cache 能够共享。通过动态调度策略实现两阶段解耦,提升有效吞吐量。
(2)长上下文输入处理优化:处理长文本输入时,GPU的显存可能无法容纳整个 KV Cache。通过引入分布式注意力算法,将 KV Cache 拆分为更小单元。采用分页注意力(Paged Attention)或块级管理,将 KV Cache切分为小块存储于多 GPU显存或 CPU 内存中,支持动态扩展。结合分布式计算框架(如Triton Inference Server)的多模型并行能力,协调车端 GPU 集群资源,实现显存与算力的动态分配。
(3)热冷神经元分层计算与异构部署:在大规模生成式模型部署时,传统的 CPU-GPU 异构计算方式可能带来较高的访存开销。采用模型切分技术,将高频激活的神经元(热神经元)保留在 GPU 显存中,低频部分卸载至 CPU 或专用 NPU,通过Zero-Inference 或 Triton 的异构计算流水线减少访存开销,从而有效减少 GPU 显存的占用,显著提高 Token 生成速度。
(4)模型动态加载与低延迟冷启动:在大规模模型部署中,实时响应是关键因素。采用轻量化引擎(如 Ollama 或 Llamafile)按需加载模型分片至 GPU,实现低延迟的冷启动。通过动态调度模型分片,确保仅加载当前任务所需的部分,从而避免不必要的全模型加载,从而显著提高推理效率和响应速度。
(5)LoRA 适配器的批处理优化:使用多个 LoRA 适配器时,将每个适配器合并为独立的模型副本会降低批处理效率。通过使用 PEFT 库的 LoRA 混合加载技术,可以在基座模型上动态切换适配器,避免生成独立的模型副本。结合vLLM的Continuous Batching 技术,支持多任务请求的并行处理,提高整体吞吐量。
异构联合计算
构建车端异构计算架构、车云协同网络及 V2X 近场算力共享机制,依托分布式计算引擎,实现跨域算力池化调度与任务动态迁移,突破单设备算力限制。
(1)车端异构计算架构。构建由CPU、GPU、NPU、VPU、MCU 等异构计算单元构成的协同计算架构,通过定制化中间件实现算力单元的深度协同。引入混合任务调度机制,对大模型推理任务进行统一调度与负载均衡,支撑模型并行执行。
1) 分布式计算引擎。整合车端异构算力构建统一的算力资源池。系统根据任务类型、优先级及节点运行状态动态分配任务,持续跟踪执行状态,保障高可用性与实时性。
2) 计算单元间通信与协同。设计统一通信协议层,打通异构芯片间的封闭壁垒。制定异构硬件间的控制面、数据面交互标准、原子操作及事务标准、状态同步标准,实现跨计算单元点对点数据通信与集群级交互。
3) 任务分配与资源管理。基于芯片特性实施任务精细分配,GPU/NPU 处理计算密集型任务如模型训练和特征提取,CPU 处理控制流与轻量任务。调度系统动态优化分配策略,实现系统级负载均衡与性能最优。任务调度系统支持多模型的并行(如快模型+慢模型,辅助驾驶模型+多模态座舱交互模型等),以及模型内计算构造块的并行。
4) 模型优化与适配。针对不同芯片架构对 AI 大模型进行精细优化。通过量化、剪枝和蒸馏等技术,降低模型参数规模与计算复杂度,提升执行效率与资源适配性。量化减少存储带宽压力,剪枝精简计算路径,蒸馏提升小模型表现,保障在各类芯片上高效运行。
5) 开发框架与工具链。构建适配异构计算的统一开发框架,支持 TensorFlow、PyTorch、OneFlow 等主流平台,集成自动微分与设备感知调度机制,实现多芯片平滑切换。配套提供性能分析与调优工具,帮助开发者快速识别瓶颈并实现高效部署。
(2)V2X 计算架构。为突破车载设备算力瓶颈、提升多车智能协同能力,构建以 V2X 为核心的通信网络与近场算力共享机制,推动车端、边缘与云端的深度协同与弹性推理调度。
1) 通信网络搭建。构建车与边缘基础设施(V2I)、车与车(V2V)等之间的通信链路,确保通信的高可靠性、低延迟和足够的带宽,以满足车辆在不同场景下的信息交互需求。
2) 边缘计算节点部署。部署边缘计算服务器,作为 V2X近场算力共享的关键节点。边缘服务器靠近车辆,对从车辆收集到的数据进行初步处理和分析,如交通状况感知、危险预警等,将结果反馈给周边车辆,减少车辆对云端的依赖。
算力共享机制设计及云边端三级协同。构建任务驱动的算力共享机制,允许车辆与边缘节点在 V2X 网络内进行算力供需协商与动态分配。进一步构建云—边—端三级协同架构,云端侧负责全局模型训练与策略优化,如交通网络级路径规划与策略调度;边缘层进行本地数据实时处理(如路况感知、短期交通流预测),提升响应效率;终端车辆(OBU)根据网络连接状态自适应切换本地推理与云端辅助决策。
基础模型层
涵盖大语言模型、视觉大模型、多模态大模型以及视觉-语言-动作模型,通过多任务协同推理和跨领域知识整合,为车载系统提供深层语义解析与环境理解能力,提升整车智能化水平。
- 大语言模型
大语言模型基于 Transformer 架构构建,通过海量语料预训练和细粒度微调,实现对自然语言的深度理解与生成。参数规模可达千亿级,主要用于自然语言处理任务,如语义理解、对话生成等,具备捕捉复杂语境和细微语义变化的能力。通过大语言模型,车载系统能够与驾驶员自然交互,提供智能语音助手、实时导航建议和个性化服务,以及车内外信息智能处理等。车载场景中,大语言模型需支持短指令快速响应、离线或弱网条件下的稳健推理,以及基于规则的安全指令过滤机制,以满足车规级的确定性和安全性要求。
- 视觉大模型
视觉大模型是基于 Transformer 架构的多尺度感知模型,通过自监督预训练和场景自适应微调,实现对复杂驾驶场景的理解。模型能够完成高精度目标检测(如交通标志、行人、车辆等)、像素级语义分割(包括车道线、可行驶区域),以及时序行为分析(如交通流预测)等关键任务。在智能座舱应用中,被广泛应用于驾驶员状态监测、手势识别和车内环境感知,从而提升驾驶安全性和用户体验。
- 多模态大模型
多模态大模型通过跨模态对齐(Cross-Modal Alignment)技术,实现对视觉、语音、点云和文本信息的联合建模。其核心架构由模态编码器、跨模态注意力层和统一表征空间构成,能够在不同数据模态之间建立高效的信息互通机制。在车载系统中,整合了各类传感器数据,形成统一的环境感知;还能支持复杂场景下多任务协同推理,显著提升系统在动态驾驶环境中的鲁棒性和泛化能力。
- 视觉-语言-动作模型
视 觉-语 言-动 作 模 型 (Vision-Language-Action Model, VLAM)是端到端智能驾驶的核心技术,通过多模态对齐和强化学习,实现从环境感知到车辆控制的闭环优化。其技术路径包含:指令嵌入、场景-指令对齐和动作生成。在智能驾驶中,视觉-语言-动作模型可以通过分析道路标志、交通信号和驾驶员指令,生成合理的驾驶决策。在智能交互中,该模型可以实现多模态的交互体验,如通过视觉和语音指令控制车内设备。
服务层
服务层构建于基础模型之上,旨在通过模块化、可扩展的服务架构,实现多场景智能应用的灵活组合与高效部署。该层主要由智能化工具服务和基础服务两大部分组成,负责将核心模型能力转化为落地应用,形成完整服务闭环。服务层需支持算力资源分配、多模型并行调度和服务治理能力,以满足多任务同时运行的实时性要求。
- 智能化工具服务
智能化工具服务通常由智驾大模型、座舱大模型等多个大模型模块,以及插件工具模块等原子服务组成,并由大模型串联各原子服务形成应用服务,为用户提供服务。
(1)原子服务:作为智能化工具服务中的最小功能单元,具有高度的独立性和可复用性。这些服务通常执行单一、明确的任务,如数据采集、信号处理、状态监测等。原子服务的优势在于其模块化设计,能够灵活组合以支持更复杂的应用场景。例如智能驾驶的原子服务包括传感器数据预处理、目标检测、路径规划等基础功能,将这些原子服务组合可以构建出更为复杂的智能驾驶功能模块,如自动泊车、车道保持等。
(2)AI Agent 基础服务:通用意义的 AI Agent 智能体实现了“以意图为中心”的 AI 与人协作机制,本平台的 AI Agent 基础服务将进一步结合 OS系统的底层能力,为智能体提供体系化、可扩展的基础服务能力。AI 大模型车载软件平台还能通过 AI Agent 基础服务,与领域 Agent 相互协作,提供全局性与专业性结合的基础服务支撑。
(3)应用服务:基于原子服务构建的更高层次的服务,实现更为复杂的功能。例如在智能座舱中,应用服务可以包括语音识别、自然语言处理、情感分析等功能模块。这些应用服务不仅能够独立运行,还可以通过接口与其他服务进行交互,形成完整的智能座舱解决方案。通过应用服务的灵活组合,智能座舱可以实现从语音控制到个性化推荐的全方位功能覆盖。应用服务可支持上下文状态保持、动态模型加载与算力自适应执行,以提高系统整体响应速度。
(4)智驾大模型:作为智能化工具服务中的核心组成部分,专注于智能驾驶领域的复杂任务处理。智驾大模型通常基于深度学习技术,能够处理多模态感知数据(如图像、雷达点云等),并实现从感知到决策的端到端优化。
(5)座舱大模型:聚焦于车内交互场景,通过车载语音交互、图像及手势交互、多模态数据交互、开放式任务等数据与任务融合,记录用户的喜好和习惯,实现人机交互、情感识别及个性化推荐,实现千人千面的座舱极致体验。
(6)底盘大模型:依托智驾域和 SOA 架构实时感知和理解驾驶场景,通过自身和更多数据,在域内、车内或边缘云端计算和自动优化底盘参数,从而提供最佳的驾驶体验。同时支持车段云端数据闭环、协同分析计算,提升模型和系统性能。
- 基础服务
基础服务层为车载大模型的全生命周期管理提供支撑,确保平台在数据安全、模型训练、运行监控等方面达到高标准要求。其主要内容包括:
(1)数据采集与隐私保护:建立严格的数据采集闭环,利用差分隐私与同态加密等技术,确保车载大模型在数据采集、传输及存储过程中对用户隐私和数据安全进行全方位保护。
(2)模型训练与更新:依托云端大模型训练服务,结合车端数据反馈,构建持续迭代与动态更新机制,确保模型在各类应用场景下始终保持高精度和鲁棒性。
(3)网联数据服务:在车联网环境下,通过高效的数据共享与协同处理机制,实现跨车辆、车云协同的数据互通,提升整体感知能力与决策效率。
(4)安全服务:构建全栈安全监控体系,集成实时入侵检测、OTA 签名验证及硬件级隔离技术,对 AI 大模型软件运行状态进行动态监控,确保系统在高实时高安全要求下稳定运行。通过智能化工具服务与基础服务的有机结合,服务层构成了一个完整的车载智能应用生态体系,不仅实现了模型能力的高效转化,还为场景应用创新和持续进化提供了有力保障。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。