



服务器
Linux服务器突然重启是什么原因?
七七
2026-01-04
1周前
在Linux服务器运维中,最让人头疼的莫过于“毫无征兆的重启”——业务中断、数据风险、排查无门… 其实只要找对方法,不用复杂操作,就能快速查清重启记录和原因!这篇干货指南,从查询到排查一步到位,新手也能轻松上手~
一、3种方法,快速查到重启记录
想解决问题,先搞懂“什么时候重启的”“重启了多少次”,这3个工具覆盖所有Linux发行版,直接复制命令就能用!
1. 最直接:who -b 一键看上次启动时间
不用翻日志,一条命令直达结果,适合快速初步判断:
who -b输出示例超直观:system boot 2025-12-21 10:32瞬间知道上次重启是12月21日上午10点32分,省去筛选麻烦~
2. 查历史:last reboot 看所有重启记录
如果想追溯最近多次重启情况,比如近10次,用这个命令:
last reboot -n 10 -F参数说明:-n 10显示最近10条,-F显示完整日期时间,输出会包含重启时间、内核版本,甚至触发方式,历史重启轨迹一目了然。
3. 查细节:日志文件精准定位
不同系统日志存储路径不同,对应命令直接用:
- • 通用版(CentOS/RHEL等):
cat /var/log/messages | grep "reboot"- • Ubuntu/Debian专用:
cat /var/log/syslog | grep "reboot"- • 现代系统(systemd):
journalctl -xb | grep "reboot"(-x会加日志解释,-b只看当前启动周期,新手也能看懂)
二、4个维度,揪出重启真凶
查到重启记录后,重点来了!从这4个方向排查,99%的原因都能找到~
1. 内核日志:查硬件/内核故障(最常见!)
服务器突然重启,大概率和硬件或内核有关,用这条命令看内核日志:
dmesg | grep -E "error|warn|fail"重点盯这几个关键词:
- • ATA error:硬盘出问题了,可能是坏道、接触不良
- • Memory error:内存故障,赶紧检测内存模块
- • kernel panic:内核恐慌,可能是内核版本不兼容或驱动问题
- • CPU overheating:CPU过热,检查风扇或散热片
2. 崩溃日志:查程序崩溃导致的重启
如果是软件崩溃引发重启,用coredumpctl工具找线索:
# 先看所有崩溃记录coredumpctl list# 再查具体详情(把1234换成实际PID)coredumpctl info 1234输出的崩溃堆栈信息,能直接定位到出问题的程序,比如某款应用、依赖库冲突等。
3. 服务+资源:查服务异常或资源耗尽
- • 服务异常:关键服务(nginx、mysql、sshd)挂了可能触发重启,查对应日志:
# nginx日志cat /var/log/nginx/error.log# mysql日志cat /var/log/mysql/error.log- • 资源耗尽:
4. 人为+计划任务:查误操作或定时任务
别忽略!可能是自己或同事误操作,或定时任务导致的:
- • 查操作记录:
history | grep "reboot"- • 查计划任务:
# 当前用户定时任务crontab -l# 系统定时任务cat /etc/crontab三、新手必避!3个常见问题解决方案
1. 查/var/log/messages没找到重启记录?
- • 换路径:Ubuntu/Debian去查/var/log/syslog
- • 查磁盘:df -h看是否磁盘满了,清理无用文件
- • 查权限:用sudo chmod 644 /var/log/messages开放读取权限
2. journalctl日志太多,看得眼花缭乱?
加参数快速筛选,只看关键信息:
# 只看错误级别+重启相关journalctl -xb -p err | grep "reboot"3. 怎么快速判断是不是硬件故障?
- • 看内核日志:有没有硬盘、内存相关错误
- • 用工具查:ipmitool看硬件状态(需支持IPMI)
- • 物理检查:服务器指示灯、风扇转不转、温度高不高
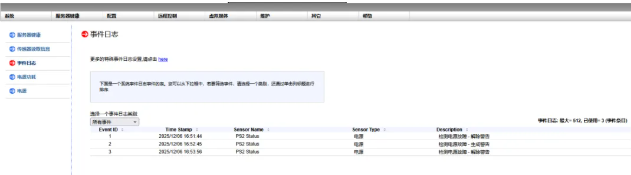
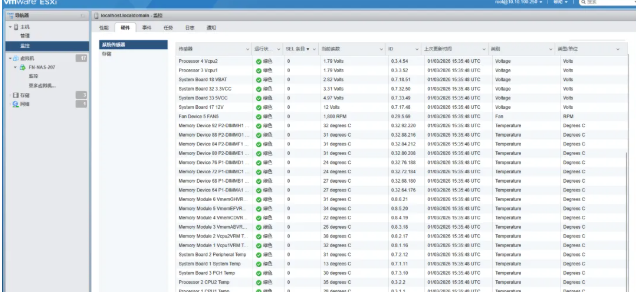
总结
Linux服务器重启排查,核心就是“先查记录,再找根源”:用who -b/last reboot快速定位时间,靠日志+工具排查硬件、软件、人为操作等原因。建议平时定期备份日志、部署监控工具,下次再遇到重启,不用慌,按这篇指南一步步来,几分钟就能搞定~
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。
分享文章