



大模型 MoE 部署避坑:从训练到推理,工程复杂度与运维管理实操技巧
在当前大模型竞争白热化的环境下,如何平衡模型性能与计算成本成为了一个重要课题。MoE(Mixture of Experts)架构正是解决这一问题的革命性方案,它让我们能用更低的成本获得媲美GPT-4的性能。
为什么需要MoE?
传统大模型面临着一个严峻的问题:性能提升需要以指数级增长的参数量和算力为代价。以GPT-3为例,其1750亿参数的训练成本高达数百万美元。这种「更大即更好」的范式显然难以持续。
核心痛点:
计算资源利用率低下
推理成本居高不下
模型部署要求苛刻
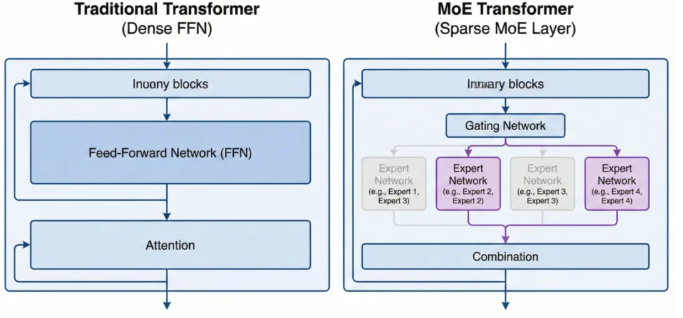
MoE架构原理深度解析
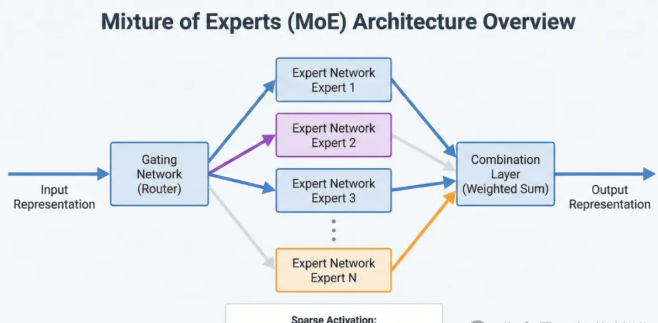
MoE的核心思想可以类比为「专家咨询系统」。想象一个大公司有多个领域专家,不同问题由相应专家处理,而不是所有问题都惊动所有专家。
关键组件
Router(路由器)
负责分析输入,决定激活哪些专家
通常采用轻量级神经网络实现
输出专家选择的概率分布
Experts(专家)
每个专家是一个独立的神经网络模块
专门处理特定类型的输入
通常共享相同的网络结构但参数不同
Gating Mechanism(门控机制)
控制专家的激活比例
实现计算资源的动态分配
优化推理效率
工程实现的关键考量
1. 负载均衡
问题:专家使用不均衡会导致性能瓶颈。
解决方案:
引入负载均衡损失函数
实现动态专家分配策略
设计自适应路由机制
2. 通信开销
在分布式环境下,专家间的通信可能成为性能瓶颈。优化方案包括:
使用稀疏注意力机制
实现高效的跨设备通信
优化数据布局和调度策略
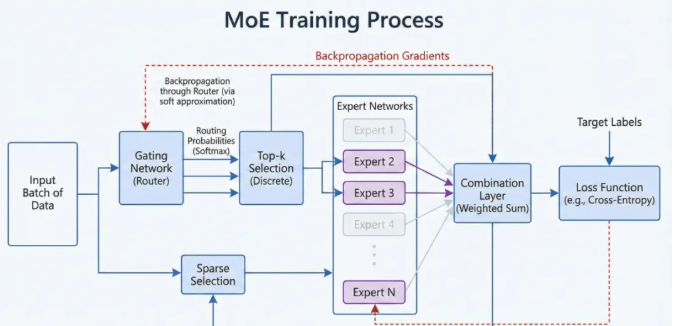
3. 训练稳定性
MoE训练比传统Transformer更具挑战性:
需要更复杂的优化器配置
要处理专家容量饱和问题
需要特殊的正则化策略
性能与成本分析
优势
计算效率
仅激活20-30%的参数即可完成推理
性能表现
在同等计算资源下提供更好的性能
可扩展性
轻松通过增加专家数量提升性能
挑战
工程复杂度
需要更复杂的部署和维护策略
训练难度
收敛过程更不稳定
通信开销
分布式场景下的瓶颈
未来展望与工程建议
混合专家策略
结合稠密与稀疏计算
实现动态专家扩展
优化专家选择算法
工程优化方向
改进负载均衡算法
优化通信架构
简化部署流程
商业价值
显著降低运营成本
提高资源利用率
支持更灵活的扩展
总结
MoE架构代表了大模型优化的未来方向。它不仅解决了计算效率问题,还为模型扩展提供了新思路。对于追求成本效益的团队来说,MoE是一个值得深入研究的方向。
记住:架构选择没有银弹,关键是根据具体场景和需求做出合适的权衡。MoE的成功实施需要在工程实现、性能优化和运维管理等多个层面都做好充分准备。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。