



95% AI 智能体部署失败!2025 最新研究:生产级智能体的 4 大实践原则
尽管AI智能体(Agent)被视为通往通用人工智能(AGI)的雏形,并有望彻底变革行业,但在实际部署中却面临着严峻的现实。
近期研究报告指出,95% 的智能体部署项目以失败告终。为了探究成功与失败之间的关键差异,来自UC Berkeley、IBM Research、Stanford University、Intesa Sanpaolo及UIUC的研究团队联合开展了这项系统性研究。
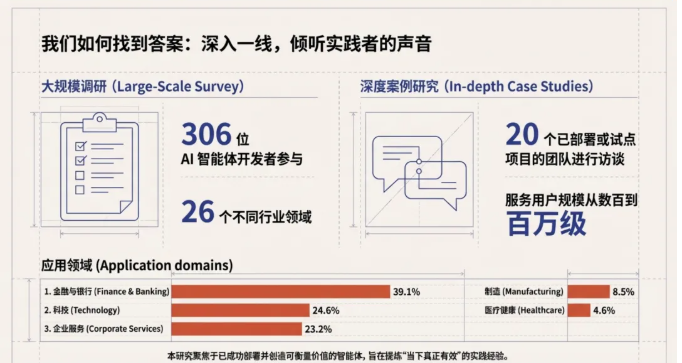
本研究并未停留在理论层面,而是深入一线,采用了大规模调研与深度案例研究相结合的方式。研究团队调研了306位AI智能体开发者,覆盖26个不同行业领域;同时对20个已部署或试点项目的团队进行了深度访谈,这些项目的服务用户规模横跨数百至百万级。
在应用领域分布上,金融与银行(Finance & Banking)占比最高,达到39.1%,其次是科技(Technology)占比24.6%,以及企业服务(Corporate Services)占比23.2%。研究聚焦于那些已成功部署并创造可衡量价值的智能体,旨在提炼出“当下真正有效”的实践经验。
01
核心洞察:生产级智能体的四大实践原则
基于海量数据与访谈,研究总结出当前生产级智能体的四大核心实践原则,涵盖了从动机到未来的完整闭环:
1. 动机(Why): 价值驱动,聚焦生产力提升。部署的首要目标必须是解决具体的业务痛点,而非单纯追求技术的先进性。
2. 构建(How - Architecture): 大道至简,倾向于可控的方案。开发者优先选择简单、可预测的架构,刻意限制智能体的自主性以换取系统的可靠性。
3. 评估(How - Evaluation): 人类验证仍是质量的“金标准”。由于任务具有高度独特性,人工审核在评估闭环中不可或缺。
4. 挑战(What's Next): 可靠性是亟待解决的核心难题。确保和评估智能体的正确性,是当前所有开发者面临的首要技术挑战。

02
动机现实:拒绝炫技,回归实效
数据明确表明,成功的智能体部署始于明确、可量化的业务问题,而非对“黑科技”的盲目探索。在构建和部署AI智能体的原因中,提升生产力(72.7%)和减少人工工时(63.6%)占据了绝对主导地位。
相比之下,出于“探索颠覆性创新”(13.2%)或“实现黑科技”(10.0%)目的的项目占比极低。这反映出行业普遍认知已回归理性:智能体的主要价值在于替代重复性人工劳动,实现业务流程的自动化,而非用于展示技术肌肉。

03
架构现实:极简主义与控制欲
在架构选择上,开发者表现出对“简单”与“可控”的极度偏好。为了保证生产环境的可靠性,绝大多数团队有意限制了智能体的自主性。数据揭示了以下现状:
- 开箱即用:70% 的深度案例直接依赖开箱即用的模型,而非进行复杂的模型微调。
- 人工构建Prompt:79% 的已部署智能体依赖人工构建提示词(Prompt),而非自动化生成。
- 限制步数:68% 的系统在需要人工干预前,执行步骤不超过10步。
这表明,生产级智能体并不需要复杂的模型微调或高度的自主规划,简单且高度可控的方法才是主流选择。
04
技术栈解密:闭源模型与自研框架的胜利
针对生产级智能体的典型技术栈,研究发现了一套标准化的构建流程,这与外界的普遍假设存在显著差异。
- 模型选择(Model Choice)绝大多数(20个案例中的17个)深度案例依赖最先进的闭源前沿模型(如GPT和Claude系列)。
- 原因分析: 尽管开源模型成本较低,但相对于其增强的人类专家成本而言,闭源模型的推理成本几乎可以忽略不计。开源模型主要用于满足特定的合规需求或极端的成本控制。
- 工作流(Workflow)预定义的结构化工作流是主流选择,而非放任智能体进行自主规划。80% 的深度案例采用了此模式。
- 典型流程示例: 一个保险智能体遵循固定序列:保障范围查询 -> 医疗必要性审查 -> 风险识别。
- 框架使用(Frameworks)在深度访谈案例中,高达 85%(17/20)的团队选择自研框架,而不是使用市面上流行的第三方库(如LangChain等)。
- 原因分析: 团队希望获得最大的灵活性和控制权,避免对第三方库的过度依赖,以便更好地适配特定业务逻辑。
05
评估现实:人类仍是最终防线
评估智能体的质量是一个复杂的过程,完全自动化的评估(仅依赖公开基准测试和量化指标)在生产环境中并不现实。
07未来画像与建议
基于2025年的现状,一个成功的生产级智能体画像通常具备以下特征:
目标: 解决具体、可量化的瓶颈,如“将处理时间从N小时缩短到M分钟”。
架构: 采用最强的前沿闭源模型,通过精巧的Prompt Engineering和结构化、步骤有限(68% ≤ 10步)的流程来驱动。
用户与环境: 主要服务于内部员工或领域专家(92.5%服务于人类用户),并有人工监督作为最终质量保障。
评估: 依赖领域专家和真实用户反馈进行持续迭代,通常需要从零构建自定义的“黄金评估数据集”。
对构建者和研究者的启示:从小处着手,聚焦可控性: 优先选择有界、可验证、有人类监督的内部任务。拥抱“人机协同”: 将人类专家视为系统能力的一部分,而非要完全取代的对象。
投资于评估体系: 构建自定义的评估框架和“黄金数据集”是成功的关键,其重要性不亚于智能体本身的开发。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。