



“大模型+临床数据”融合关键路径

我们正站在医疗智能化的拐点。大模型技术以其强大的推理与生成能力,正迅速渗透至临床研究的各个环节,重塑从数据管理到诊疗决策的传统范式。本文旨在系统梳理当前临床数据管理的核心挑战,探讨大模型在其中的创新应用,并构建一套分层、分阶段的可行路径,以推动数据资产向临床价值的有效转化,为医疗行业的智能化升级提供方法论支撑。
一、临床数据管理现状与挑战:从“4V”特性到系统壁垒
大模型重构临床研究范式的进程中,临床数据质量权重逐渐上升,多元结构类型的整合价值远超单纯规模堆叠,对临床决策具有重要支撑意义。其价值释放始于对其本质特征的深刻理解,可概括为“4V”特性,即:
- 规模性 (Volume),大数据的首要特征体现为“数量大”,以TB级别起步;
- 多样性 (Varity),大体可分为三类:数据间因果关系强的结构化数据(如医疗系统数据等),数据间没有因果关系的非结构化数据(如视频、音频,影像,波形等);数据间因果关系弱的半结构化数据(如HTML文档、邮件、网页等),共同构成AI分析的完整维度;
- 高速性 (Velocity) , 主要体现在数据交换、数据响应、数据处理(实时而非批量分析)、数据增长速度等方面,对处理时效性要求极高,尤其在急诊等场景中直接关联诊疗质量与患者生命;
- 价值性 (Value),大数据的核心特征,即通过AI数据挖掘,可以提供未来趋势与预测价值的数据,发现新规律和新知识。
然而,这些特性也同步放大了临床数据管理的三重挑战:
系统端,数据分散于 EMR(电子病历)、LIS(实验室信息系统)、PACS(影像归档系统)、HIS(医院信息系统)及病理、组学数据库等数十套异构平台;
维度上,覆盖检验类结构化数据、病历类半结构化数据、影像与文本类非结构化数据,天然形成多模态特征;
交互层面,国内医院普遍存在 “分散存储、标准化缺失、互通性不足” 困境。即便临床开发领先的华西医院,历经多年建设仍未实现数据全贯通,且缺乏语义标注与统一调度平台,进一步加剧管理壁垒 。
现实中,“中国不缺医疗数据”的共识背后,实则是“信息泛滥而可用数据匮乏”的窘境:病历结构化率低,依赖手工录入且模板不统一;数据普遍存在缺失、冗余、冲突,版本历史记录缺失;医院间标准不一,科研队列复用难度高;合规治理趋严,伦理审批、数据脱敏与用途限定环环约束 。如图1所示,数据质量已成为最显著短板,而互操作性、可复用性与隐私合规亦亟待提升。究其根本,国内缺乏统一的医疗数据治理标准体系,导致数据价值难以规模化释放。
二、大模型赋能临床研究:从辅助工具到范式重构
大模型的出现为上述困境提供了突破路径。其价值不仅体现为效率提升工具,更在于推动研究范式从传统的“假设-验证”向“数据-学习-知识迁移”动态迭代转型。同时,大语言模型(LLM)作为 “语义引擎” ,可自动生成病历摘要、标注关键数据辅助诊断。多模态模型更突破单一维度限制,实现 CT 影像、基因测序与病历文本的 共模学习 ,挖掘复杂关联规律, 三者协同推动临床决策从经验主导向数据驱动的精准化范式演进。
具体而言,大模型在临床中的应用沿“功能×数据类型”矩阵展开:文本挖掘与理解、影像 - 组学融合、知识管理、预测与预后四大功能,覆盖病历文本、医学影像、基因组学、临床试验及真实世界数据五大维度 。
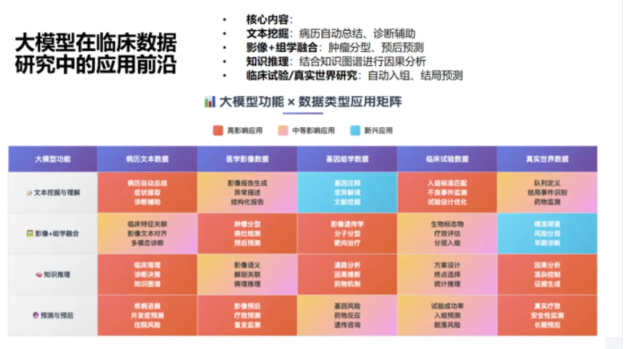
值得关注的是,大模型正逐步重塑医疗职业边界。“大模型是否真的可以取代医生呢?”,当前放射科、外科等领域首当其冲:多模态模型替代部分影像判读工作,而“大模型+机械臂”甚至可自主完成手术设计与操作,超越人类毫米级操作精度局限。这无一不体现临床决策体系正从经验依赖转向数据驱动。
三、融合实践路径及其分层架构
为实现数据管理与大模型的有效融合,需遵循“治理-训练-工具-应用”四层推进路径:
第一,数据治理以 FHIR 标准为核心框架(虽非唯一,适配性已获验证),搭配统一编码体系(如 ICD 编码)落地;第二,模型训练通过联邦学习、差分隐私等隐私计算技术实现突破数据孤岛与隐私壁垒,支撑跨机构协作,隐私保护进入全新范式;第三,智能管理工具聚焦大模型驱动的 “脏活累活”,自动完成数据清洗、标签化与溯源,替代人工繁琐流程,为后续分析奠定基础;第四,临床应用指向科研一体化平台与智能 CDSS(临床决策支持系统),推动 “冷数据” 向 “活资产” 转化,实现从治理到落地的闭环 。
还需分层金字塔架构,适配医疗数据 “不可离院” 的红线约束:
- 技术架构:三层金字塔逻辑
底层——临床应用与科研平台:搭建通用数据模型与医疗互操作性资源,同时由于大模型与数据先天绑定,需保证数据质量管理、元数据治理、安全合规,保障安全合规(技术支撑:FHIR、Data Governance、Security Compliance)。
中层——隐私计算与模型训练:部署联邦学习、差分隐私、同态加密等隐私计算技术,推进大模型训练、多模态融合与知识蒸馏。但联邦学习挑战颇多,因为医疗数据不可物理迁移,需解决数据溯源、粉碎与可信区间构建等问题,数据编织技术或成破局方向。当前国内大模型多模态能力仍存短板,待持续突破。
上层——临床应用与科研平台:落地智能诊断、精准医疗、药物研发及临床决策支持系统(CDSS),构建科研协作平台。目标指向 “个体化精准决策”,预计 3 - 5 年涌现成熟应用,技术依托临床 AI 与平台化协作。
这套体系既可回应 “数据不可离院” 的现实约束,又能通过分层解耦、阶段推进,实现大模型从训练到临床落地的闭环。其原创性阶段划分,或许能为医疗 AI 工业化落地提供了可对标、可演进的路径参考。
四、未来展望与治理思考
面向未来,三大方向将成为突破关键:
第一,采用“专科化小模型+通用大模型混合架构”,以突破 “算力陷阱” 与资源马太效应 困局。大模型对算力、算法工程师及数据的极致要求,使头部三甲医院凭借技术壁垒进一步拉开差距,下级医院传统 “进修学习” 路径失效。基层医疗与药企可聚焦专属领域训练小模型,既规避算力军备竞赛,又能通过通用大模型调用共性能力,实现资源适配。
第二,跨机构数据共享与联邦化研究,其核心痛点为质量参差与标准异构 ,需国家主导推进编码体系、治理规范统一,为联邦化研究与数据交易扫清障碍。
第三,区块链与 AI 的融合,则可通过 精准溯源 确保数据可信流通:既为医患纠纷、数据交易提供存证依据,也赋能 “医生画像”(整合诊疗轨迹,辅助患者精准匹配)与 “病人画像”(实现数据资产化,惠及后代或商保),优化医疗资源配置效率。
未来 3 - 5 年,专科小模型架构、跨机构标准共建、区块链 + AI 溯源将成突破门槛,虽数据清理模式、系统异构等难题仍存,但三者协同已勾勒出医疗数据从 “割据” 到 “可信流转” 的进化路径。
写在最后
大模型正以强大推理能力,重塑临床数据研究与管理范式,尤其在医疗场景的不确定性决策中展现独特价值 。数据治理与大模型的融合是医疗智能化核心 —— 医疗场景天然的多模态特性(影像、文本、组学等),决定了唯有打破数据壁垒、实现跨类型整合,才能释放模型效能 。跨学科合作(医疗与 AI 技术协同)及合规治理是发展关键:既需推动医生理解 AI 逻辑、工程师洞察医疗场景,更要以合规框架保障数据与决策安全,让技术兼具 “智能” 与 “仁心” 。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。