



什么是大模型智能体?
一、简单理解
这篇文章核心是用通俗的方式讲“大模型智能体(LLM Agent)”——简单说就是给普通大模型装了“脑子+手脚+记忆”,让它从只会“聊天”变成能自主完成复杂任务的“小助手”。
1. 先说说普通大模型的短板
普通大模型就像“健忘的学霸”:只会顺着话茬往下说,记不住之前的对话(比如问完1+1再问刚才问了啥,它会忘),不会算复杂数学题、查实时信息,也做不了需要分步推进的事。
2. 大模型智能体的“三大外挂”(核心组件)
为了补短板,智能体加了三个关键“外挂”,让大模型变能干:
- 记忆
- 工具
- 规划
3. 让智能体“会思考、能纠错”的技巧
光有外挂还不够,还得教它“怎么用”:
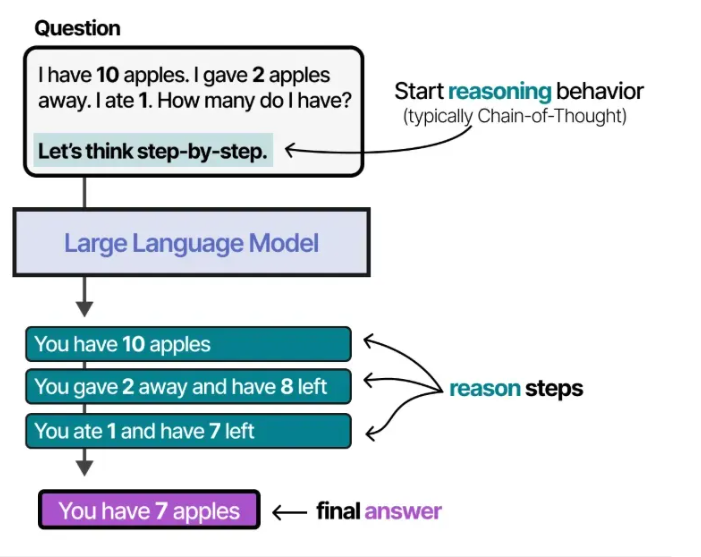
- 用“思维链”让它慢慢想:比如问“10个苹果送2个、吃1个,剩几个”,它会一步步算,不是直接猜答案。
- 用ReAct框架让它“边想边做”:先分析情况→再选工具行动→最后看结果调整,形成循环。
- 加“反思”功能:做错题或没做好时,能自己复盘,下次改进(比如这次搜错资料,下次会换关键词)。
4. 多智能体协作:多个“小助手”一起干活
单个智能体处理复杂任务会吃力,于是就有了“多智能体”——比如一个负责查资料、一个负责写代码、一个负责总结,还有个“协调者”分配任务,各司其职效率更高。
总的来说,这份文档本质就是讲:大模型智能体不是天生厉害,而是靠“记忆+工具+规划”这三大核心,再加上“思考、行动、反思”的流程,甚至多个智能体配合,才从“只会聊天”变成能自主完成工作、解决问题的实用工具,现在相关技术和框架也越来越成熟了。
二、原文部分
大模型智能体正日益普及,其风头似乎已盖过我们所熟悉的常规对话式大模型。然而,这些强大功能的实现并非易事,需要众多组件协同运作才能达成。
一、何为“大模型智能体”?
要理解什么是大模型智能体,我们首先需要了解大语言模型的基本能力。传统上,一个大语言模型仅仅执行“下一词预测”的任务。

通过连续采样生成多个词元,我们可以模拟对话,并利用大语言模型为我们的问题生成更详尽的答案。
然而,当我们持续进行“对话”时,任何大语言模型都会暴露出其主要缺陷之一:它无法记住对话内容!
大语言模型常常无法完成的任务还有很多,包括像乘除法这样的基础数学运算:
这是否意味着大语言模型一无是处呢?当然不是!我们并不需要大语言模型无所不能,因为可以通过外部工具、记忆和检索系统来弥补其缺陷。
借助外部系统,大语言模型的能力可以得到增强。Anthropic 公司将此称为 “增强型大语言模型”。
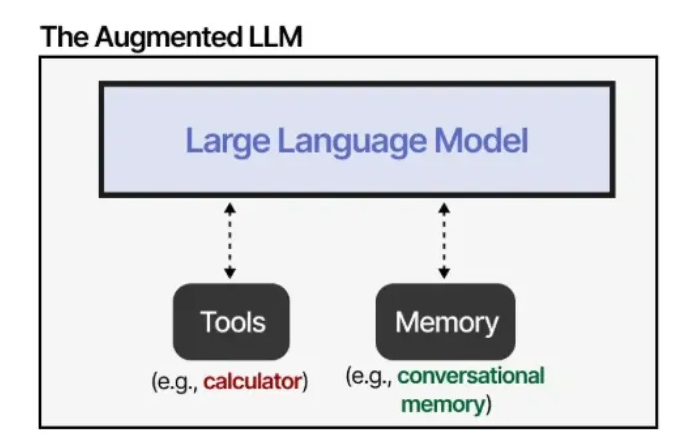
例如,当遇到一个数学问题时,大语言模型可以决定使用合适的工具(比如一个计算器)。
那么,这种“增强型大语言模型”就是智能体了吗?不完全是,但也可能沾点边……
让我们从智能体的定义开始:¹
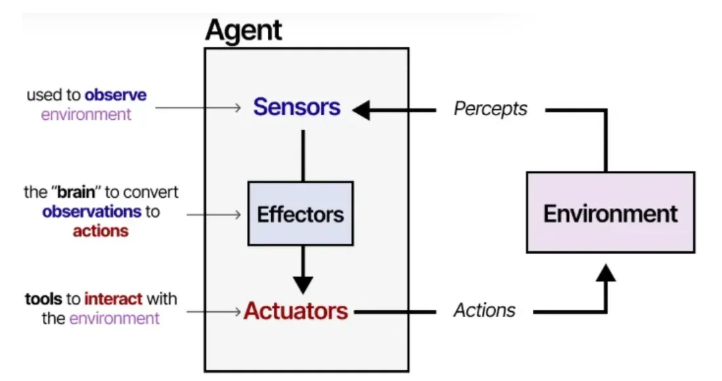
智能体是指任何能够通过传感器感知其环境,并通过执行器对该环境施加作用的事物。— Russell & Norvig, 《人工智能:一种现代方法》(2016)
智能体通过与环境的交互来运作,通常包含以下几个关键组件:
- 环境 —— 智能体与之交互的世界
- 传感器 —— 用于观察环境
- 执行器 —— 用于与环境交互的工具
- 效应器 —— 决定如何从观察转为行动的“大脑”或规则
这一框架适用于所有与环境交互的各类智能体,例如与现实物理环境交互的机器人,或与软件环境交互的AI智能体。
我们可以对此框架稍作概括,使其更适合“增强型大语言模型”。
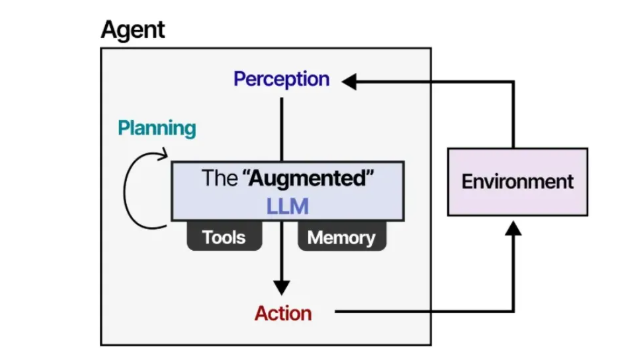
借助“增强型”大语言模型,智能体可以通过文本输入(因为大语言模型本质上是文本模型)来观察环境,并通过使用各种工具(例如网络搜索)来执行特定动作。
为了选择要采取的行动,大模型智能体拥有一个至关重要的组件:规划能力。为此,大语言模型需要能够通过思维链 等方法进行“推理”和“思考”。
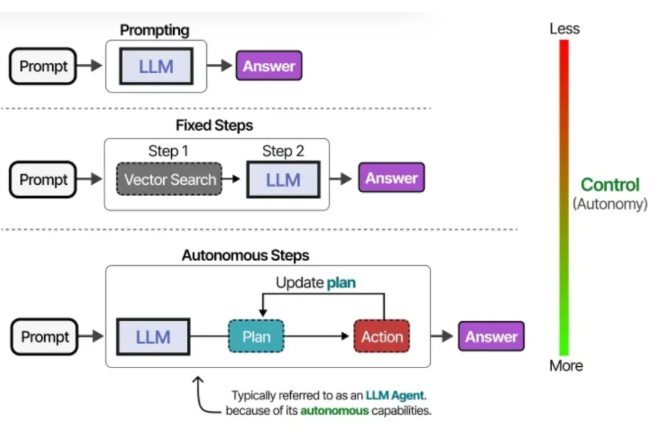
根据系统设计的不同,大模型智能体可以拥有不同程度的自主性。
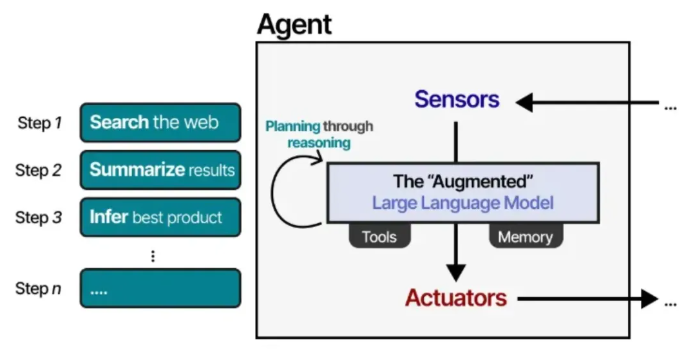
根据不同的理解,一个系统的“智能体”程度越高,通常意味着大语言模型在决定系统行为方面拥有更大的自主权。
在接下来的章节中,我们将通过大模型智能体的三个核心组件:记忆、工具和规划,来深入探讨实现自主行为的各种方法。
记忆
大语言模型本身是健忘的系统,或者更准确地说,在与它们交互时,它们根本不执行任何记忆功能。
例如,当你向大语言模型提问,随后又提出另一个问题时,它并不会记住之前的内容。

我们通常将此称为短期记忆,也称为工作记忆,它充当(近)即时上下文的缓冲区。这包括大模型智能体近期采取的行动。
然而,大模型智能体还需要跟踪可能多达几十个步骤,而不仅仅是最近的动作。
这被称为长期记忆,因为从理论上讲,大模型智能体可能执行了数十甚至数百个需要被记住的步骤。
让我们来探讨几种赋予这些模型记忆能力的技巧。
短期记忆
实现短期记忆最直接的方法是使用模型的上下文窗口,这本质上是一个大语言模型能够处理的词元数量。
上下文窗口的大小通常至少为 8192 个词元,有时甚至可以扩展到数十万个词元!
一个大的上下文窗口可以用来存储完整的对话历史,并将其作为输入提示的一部分。
只要对话历史没有超出大语言模型的上下文窗口,这种方法就有效,并且是模拟记忆的一种好方法。然而,这并不是真正地"记住"对话,我们实质上是在"告诉"大语言模型之前的对话内容是什么。
对于上下文窗口较小的模型,或者当对话历史很长时,我们可以使用另一个大语言模型来总结迄今为止的对话。
通过持续总结对话,我们可以保持这部分对话内容的小体量。这将在减少词元数量的同时,只跟踪最关键的信息。
长期记忆
大模型智能体中的长期记忆,包括需要在较长时间内保留的智能体过去的行动空间。
实现长期记忆的一种常用技术是将之前所有的交互、行动和对话存储在一个外部的向量数据库中。
要构建这样的数据库,首先需要将对话嵌入到能够捕捉其含义的数值表示中。
构建数据库后,我们可以对任何给定的提示进行嵌入,并通过比较提示嵌入与数据库中的嵌入,在向量数据库中找到最相关的信息。
这种方法通常被称为检索增强生成(RAG)。
长期记忆还可能涉及保留不同会话中的信息。例如,您可能希望一个大模型智能体记住它在之前会话中做过的任何研究。
不同类型的信息也可能与要存储的不同类型的记忆相关联。在心理学中,需要区分多种记忆类型,《语言智能体的认知架构》论文将其中的四种与大模型智能体关联起来:²
- 工作记忆 -> 短期上下文
- 情景记忆 -> 长期、特定经历和事件
- 语义记忆 -> 世界知识/事实
- 程序性记忆 -> 技能和工具使用)
这种区分有助于构建智能体框架。例如,语义记忆(关于世界的事实)可能与工作记忆(当前和近期的情况)存储在不同的数据库中。
工具
工具使得大语言模型能够与外部环境(例如数据库)进行交互,或使用外部应用程序(例如运行自定义代码)。

工具通常有两种用途:获取数据以检索最新信息,以及执行操作,例如安排会议或订购食物。
要实际使用一个工具,大语言模型必须生成符合该工具 API 接口规范的文本。我们通常期望生成的字符串能够格式化为 JSON,以便轻松地馈送给代码解释器。
请注意,这并不局限于 JSON,我们也可以在代码本身中调用工具! 您还可以生成大语言模型可以使用的自定义函数,例如一个基本的乘法函数。这通常被称为函数调用。
有些大语言模型如果得到正确且详尽的提示,可以使用任何工具。工具使用是当前大多数大语言模型都具备的能力。
一个更稳定的使用工具的方法是通过对大语言模型进行微调(后续详述!)。
工具的使用方式可以是:如果智能体框架是固定的,则按既定顺序使用……
……或者大语言模型可以自主选择使用哪个工具以及何时使用。如上图所示,大模型智能体本质上是一系列的大语言模型调用(但具有对动作/工具等的自主选择能力)。
换句话说,中间步骤的输出会被反馈给大语言模型以继续处理。
Toolformer
工具使用是增强大语言模型能力并弥补其缺陷的强大技术。因此,在过去几年中,关于工具使用和学习的研究努力迅猛增长。

这类研究大多不仅涉及通过提示来让大语言模型使用工具,还包括专门为工具使用而训练它们。
其中最早的技术之一叫做 Toolformer,这是一个经过训练、能够决定调用哪个 API 以及如何调用的模型。³
它通过使用 [ 和 ] 这两个词元来指示调用工具的开始和结束。当收到一个提示,例如“5 乘以 3 是多少?”时,它开始生成词元,直到遇到 [ 词元。
之后,它继续生成词元,直到遇到→词元,这表示大语言模型停止生成。
接着,工具将被调用,其输出将被添加到迄今为止生成的词元中。
Toolformer 通过精心生成一个包含许多工具使用示例的数据集供模型训练,从而创建了这种行为。对于每个工具,手动创建少量示例提示,并用于采样那些使用这些工具的输出。
这些输出会根据工具使用的正确性、输出结果以及损失函数的降低情况进行过滤。最终得到的数据集用于训练一个大语言模型,使其遵循这种工具使用的格式。
自 Toolformer 发布以来,出现了许多令人兴奋的技术,例如能够使用数千种工具的 LLMs(ToolLLM⁴),或者能够轻松检索最相关工具的 LLMs(Gorilla⁵)。
无论如何,当前(2025 年初)大多数的大语言模型都已经通过生成 JSON 的方式(如我们之前所见)被训练得能够轻松调用工具。
模型上下文协议 (MCP)
工具是智能体框架的重要组成部分,使大语言模型能够与世界互动并扩展其能力。然而,当存在许多不同的 API 时,启用工具使用变得很麻烦,因为任何工具都需要:
- 手动跟踪并提供给大语言模型
- 手动描述(包括其预期的 JSON 模式)
- 在其 API 变更时手动更新
为了使工具在任何给定的智能体框架中更容易实现,Anthropic 开发了模型上下文协议 (MCP)。⁶ MCP 为天气应用、GitHub 等服务标准化了 API 访问。
它包含三个组件:
- MCP 主控端
- MCP 客户端
- MCP 服务器
例如,假设您希望某个 LLM 应用程序总结您代码库中最近的 5 次提交。
1、MCP 主控端(与客户端一起)会首先调用 MCP 服务器询问有哪些工具可用。
2、LLM 接收到信息,并可能选择使用一个工具。它通过主控端向 MCP 服务器发送请求,然后接收结果,包括所使用的工具信息。
3、最后,LLM 接收到结果,并可以解析出答案给用户。
这个框架通过连接到任何 LLM 应用程序都可以使用的 MCP 服务器,使得创建工具变得更加容易。因此,当您创建一个与 Github 交互的 MCP 服务器后,任何支持 MCP 的 LLM 应用程序都可以使用它。
规划(Planning)
工具使用能让大语言模型(LLM)拓展自身能力边界,调用工具通常采用类 JSON 格式的请求。
但在智能体系统中,大语言模型如何判断该使用哪种工具、何时使用呢?
这正是 “规划” 的核心作用。大模型智能体(LLM Agent)中的规划,是指将给定任务拆解为可执行的具体步骤。
通过这份规划,模型能够迭代反思过往行为,并在必要时更新当前规划。
当计划顺利推进时,效果真的很棒!要在大模型智能体中实现规划功能,我们首先需要了解这一技术的基础 —— 即推理(Reasoning)。
推理(Reasoning)
制定可执行步骤需要复杂的推理能力。因此,大模型在推进任务规划前,必须具备这种推理能力。
“具备推理能力的大语言模型”,指的是那些在回答问题前会先 “思考” 的模型。
这里我对 “推理” 和 “思考” 的使用较为宽泛 —— 毕竟我们可以争论这是否属于类人思考,还是仅仅将答案拆解为结构化步骤。
这种推理能力大致可通过两种方式实现:对大语言模型进行微调,或采用特定的提示工程。
借助提示工程,我们可以提供推理过程的示例,引导大模型遵循。提供示例(也称为 “少样本提示” 7)是调控大模型行为的有效方法。

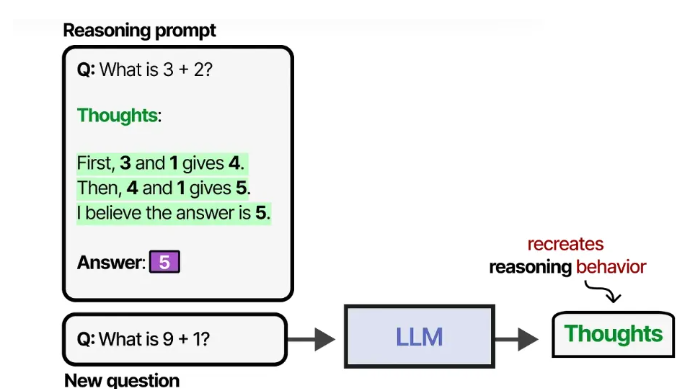
这种提供思考过程示例的方法被称为 “思维链(Chain-of-Thought)”,能让模型展现更复杂的推理能力 8。
思维链也可在不提供任何示例的情况下启用(即 “零样本提示”),只需简单告知模型 “让我们一步步思考” 9。
训练大语言模型时,我们既可以为其提供足量包含类思考过程的数据集,也可以让模型自行探索思考流程。
深度求索(DeepSeek-R1)就是一个典型案例,该模型通过奖励机制引导思考过程的运用。
推理与行动(Reasoning and Acting)
让大语言模型(LLM)具备推理能力固然很好,但这并不意味着它能规划出可执行的具体步骤。
我们目前聚焦的技术,要么仅展现推理行为,要么仅通过工具与环境交互。
例如,思维链(Chain-of-Thought)就纯粹聚焦于推理过程。
首个将这两个过程结合的技术之一是 ReAct(全称 Reason and Act,译为 “反应式框架”)¹⁰。

ReAct 通过精细化的提示工程实现这一融合,其提示词包含三个核心步骤:
- 思考(Thought)—— 对当前情况的推理分析步骤
- 行动(Action)—— 待执行的一系列操作(如调用工具)
- 观察(Observation)—— 对行动结果的推理分析步骤
该提示词本身设计得十分简洁明了。
大语言模型会借助这份提示词(可作为系统提示词使用),将自身行为引导至 “思考 - 行动 - 观察” 的循环模式中。
这种循环会持续进行,直到某一行动明确指令返回结果为止。通过反复迭代思考与观察,大语言模型能够规划行动、观察输出结果,并据此做出相应调整。
因此,与那些步骤固定的智能体相比,该框架能让大语言模型展现出更强的自主智能体行为。
反思(Reflecting)
没有任何智能体 —— 即便是搭载 ReAct 框架的大语言模型 —— 能完美完成所有任务。只要能从过程中反思,失败本身就是流程的一部分。
ReAct 框架恰好缺少这种反思机制,而 “反思机制(Reflexion)” 正是为弥补这一缺口而生。这是一种通过语言强化信号,帮助智能体从过往失败中学习的技术 ¹¹。
该方法为大语言模型设定了三个角色:
- 执行者(Actor)—— 基于状态观察选择并执行行动,可采用思维链或 ReAct 等方法。
- 评估者(Evaluator)—— 对执行者产生的输出结果进行评分。
- 自我反思模块(Self-reflection)—— 反思执行者的行动及评估者给出的评分。
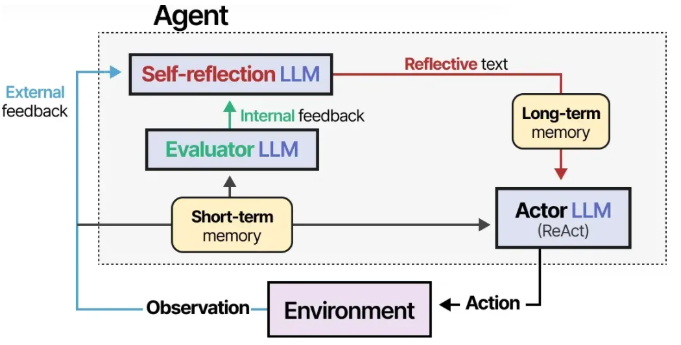
系统会添加记忆模块,用于追踪行动(短期记忆)和自我反思内容(长期记忆),帮助智能体从错误中学习,找到更优的行动方案。
另一种类似且简洁的技术是 “自我优化框架(SELF-REFINE)”,其核心是重复执行输出优化与反馈生成的动作 ¹²。
同一大语言模型需同时负责生成初始输出、优化后输出以及反馈内容。
有趣的是,无论是反思机制(Reflexion)还是自我优化框架(SELF-REFINE),这种自我反思行为都与强化学习高度相似 —— 后者会根据输出质量给予奖励信号。
多智能体协作(Multi-Agent Collaboration)
我们之前探讨的单一智能体存在一些问题:工具过多可能增加选择难度,上下文会变得过于复杂,且部分任务需要专业领域的专精能力。
因此,我们可以转向多智能体框架(Multi-Agents)—— 由多个智能体组成,每个智能体都具备工具调用、记忆存储和规划能力,它们之间以及与环境之间可进行交互:
这类多智能体系统通常包含多个专精型智能体,每个都配有专属工具集,并由一个 “协调者(supervisor)” 进行管理。协调者负责统筹智能体之间的通信,还能将特定任务分配给对应的专精型智能体。
每个智能体可调用的工具类型可能不同,所搭载的记忆系统也可能存在差异。
在实际应用中,多智能体架构已有数十种,但核心均包含两个组件:
- 智能体初始化(Agent Initialization)—— 如何创建单个(专精型)智能体?
- 智能体协调调度(Agent Orchestration)—— 如何统筹协调所有智能体?
下面我们将介绍几种有趣的多智能体框架,并重点说明这两个核心组件的实现方式。
人类行为的交互式模拟体(Interactive Simulacra of Human Behavior)
有一篇多智能体领域极具影响力、且设计十分精妙的论文 ——《生成式智能体:人类行为的交互式模拟体》(Generative Agents: Interactive Simulacra of Human Behavior)¹³。
该论文中提出了一种计算软件智能体,能够模拟逼真的人类行为,研究者将其命名为 “生成式智能体(Generative Agents)”。
每个生成式智能体都被赋予专属档案,这让它们的行为具有独特性,进而产生更有趣、更具动态性的交互表现。
每个智能体初始化时都会搭载三个模块(记忆模块、规划模块和反思模块),与我们之前介绍的 ReAct 和 Reflexion 框架的核心组件高度相似。
记忆模块是该框架中最关键的组件之一,它不仅存储规划和反思行为,还会记录迄今为止发生的所有事件。
当智能体面临下一步行动或接收问题时,系统会检索相关记忆,并根据时效性、重要性和相关性进行评分,得分最高的记忆会提供给智能体参考。
这些模块共同作用,让智能体能够自主开展行为并相互交互。因此,该框架中几乎不需要复杂的智能体协调调度 —— 因为智能体没有预设的明确目标。
这篇论文中有很多精彩的内容,这里重点介绍其评估指标 ¹⁴。
该研究以智能体行为的 “逼真度” 作为核心评估指标,并由人类评估者进行打分。
这一评估结果表明,观察、规划和反思三者结合,对生成式智能体的性能至关重要。正如之前所探讨的,缺乏反思行为的规划是不完整的。
模块化框架(Modular Frameworks)
无论选择哪种多智能体系统构建框架,其核心构成要素通常包括:智能体档案、环境感知能力、记忆存储、规划能力和可用行动集 ¹⁵¹⁶。
实现这些组件的主流框架有 AutoGen¹⁷、MetaGPT¹⁸和 CAMEL¹⁹,但每种框架在智能体通信机制的设计上略有不同。
以 CAMEL 为例,用户首先提出问题,并定义 “AI 用户(AI User)” 和 “AI 助手(AI Assistant)” 两个角色。其中,AI 用户角色模拟人类用户的需求,主导整个协作流程。
之后,AI 用户和 AI 助手通过相互交互,共同协作解决用户提出的问题。
这种角色扮演模式,实现了智能体之间的协作式通信。
AutoGen 和 MetaGPT 采用了不同的通信方式,但核心都在于这种协作式交互 —— 智能体有机会通过沟通更新自身状态、目标和下一步行动规划。
在过去一年,尤其是最近几周,这些框架的发展势头极为迅猛。

随着框架的不断成熟与完善,2025 年必将成为令人振奋的一年!
总结(Conclusion)
以上就是我们关于大模型智能体(LLM Agents)的全部探讨!希望本文能帮助你更好地理解大模型智能体的构建逻辑。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。