



AI领域常见名词与概念有哪些?
AI进入了爆发式增长阶段,每周都有大量的信息涌出,很多名词都是这次行业浪潮新出现的。沟通阅读中最大的障碍之一就是对别人作为缺省知识的名词自己还是似懂非懂。
所以这篇文章收集解释几个经常遇到的 AI 术语。希望能够在阅读之后大幅减少阅读相关内容的障碍。
一、Token:一个词,五种意思
Token 这个词在不同场景下意思完全不同。我们需要根据上下文判断它指的是哪一种。
1. AI 领域:文本的计量单位
这是最常遇到的用法。AI 模型(ChatGPT、Claude 等)不是按“字”或“词”处理文本,而是把文本切成 token。一个 token 可能是一个字、一个词、或者词的一部分。
为什么你需要关心:
- 计费依据: AI 服务按 token 数收费。GPT-4 输入 ,输出0.06/1K tokens。你发的问题和 AI 的回答都要算钱。
- 长度限制:每个模型有 token 上限。GPT-4 是 8K-128K, Claude 3 是 200K。超过了就会截断或报错。
- 响应速度: token 越多,处理越慢。
粗略换算:
- 中文:1-2 个汉字 ≈ 1 token
- 英文:一个词或词的一部分 ≈ 1 token
- 标点符号:通常 1 个
实用建议:
- 提问别啰嗦
- 长文档分段处理
- 注意工具显示的 token 用量
2. 安全领域:访问凭证
这是我们配置 API、登录系统时遇到的那串长字符串。
常见类型:
API Token/API Key
- 调用第三方服务的密钥(如 OpenAI API)
- 格式:sk-proj-abc123xyz789...
- ⚠️ 绝对不能泄露,别人拿到就能用你的账户消费
Session Token
- 保持登录状态的凭证
- 存在浏览器 cookie 里
- 有效期几小时到几天
OAuth Token
- “用微信登录”这类第三方授权
- Access Token(短期)+ Refresh Token(长期)
Telegram Bot Token
- Telegram 机器人的身份凭证
- 格式:123456789: ABCdefGHIjklMNOpqrsTUVwxyz
- 通过 @BotFather 申请
JWT(JSON Web Token)
- 包含用户信息的自验证凭证
- 格式:header.payload.signature
3. 区块链领域:代币
基于区块链发行的数字资产。
Token vs Coin:
- Coin(币):Coin 拥有自己独立的底层区块链网络,并在该网络中作为原生资产运行。如比特币(BTC)、以太坊(ETH)。
- Token(代币):Token 没有自己独立的区块链,而是依托于现有的其他区块链网络构建和运行。如 USDT、各种项目代币
主要类型:
- 功能型代币:在特定平台使用,如 Filecoin(买存储空间)
- 治理代币:投票决定项目方向,如 Uniswap(UNI)
- 稳定币:锚定法币,如 USDT(1 USDT ≈ 1 美元)
- NFT:独一无二的数字资产,如数字艺术品
- ⚠️风险警告:价格剧烈波动、诈骗项目泛滥、监管不确定、技术门槛高。
4. 编程领域:词法单元
编译器把源代码分解成的最小语法单位。例子:
intx =10;
被分解为:
int→ 关键字
x→ 标识符
=→ 运算符
10→ 数字
;→ 分隔符 这是编译原理的基础概念,只有极少数这个领域专业人员会遇到。
5. 日常用语:象征、标志
- “a token of appreciation”(感谢的象征)
- “token gesture”(象征性的姿态,敷衍的意思)
- “token woman”(装点门面的女性,政治正确的象征性任命)
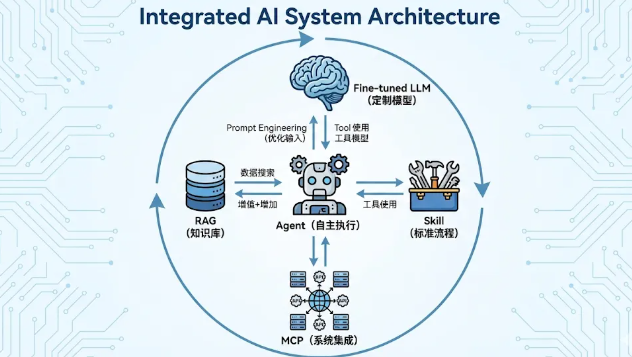
二、Agent:能自己干活的 AI
什么是 Agent
传统 AI 是“一问一答”。Agent 是“给个目标,自己想办法完成”。
核心区别:
传统 AI:你问“明天天气怎么样”,它回答“晴天”
Agent:你说“帮我订明天去上海的机票,预算 1000 以内”,它自己搜索、比价、下单
四个关键特征:
- 自主性:不需要你每步都指挥
- 反应性:能感知环境变化并调整
- 主动性:会主动采取行动达成目标
- 社交能力:能和其他 Agent 或人协作
Agent 怎么工作
基本架构:
Agent = LLM(大脑) + Memory(记忆) + Planning(规划) + Tools(工具)
- LLM:提供推理和决策能力
- Memory:记住过去的对话和经验
- Planning:把复杂任务拆成子任务
- Tools:调用搜索、计算、API 等外部工具
典型流程:

现有的 Agent 产品
- Claude Code: Anthropic 的编程 Agent,算是影响最广泛的应用之一了,可以实现vibe coding,就是让完全不懂编程的人,只要说明了逻辑关系,就可以写出一个像样的程序来
另外还有其他的Agent产品:
- OpenAI Operator(2025.1):能控制浏览器完成任务
- AutoGPT(2023):最早的开源自主 Agent
- AutoGLM(2025.12):支持微信、淘宝等 50+ 中文应用
Agent 的问题
- 可靠性:可能做出错误决策
- 成本:多次 API 调用,费用快速增长
- 安全性:自主性越高,风险越大
- 可控性:如何确保它按你的意图行事
三、MCP: AI 的 USB-C 接口
什么是 MCP
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 在 2024.11 推出的开源标准,用于连接 AI 应用和外部系统。
解决的问题:
以前每个 AI 工具要连接每个数据源,都得单独开发插件。ChatGPT 连 Google Drive 要一个插件,连 Notion 又要另一个。开发者要维护一堆重复代码。 有了 MCP,开发者只需实现一次标准接口,所有支持 MCP 的 AI 工具都能自动连接。
类比:
- 没有 MCP:每个手机品牌都有专用充电器,你得带一堆线
- 有了 MCP:所有设备都用 USB-C,一根线通用
MCP 的三个核心组件
- Resources(资源): AI 可以读取的数据源(文件、数据库、API 数据)
- Tools(工具): AI 可以调用的功能(搜索、计算、发邮件)
- Prompts(提示词模板):预定义的提示词和工作流
实际应用场景
个人使用:
- Claude Desktop 连接你的 Google Drive、Notion、本地文件
- 一次配置,所有文档都能被 AI 访问
企业使用:
- 连接公司内部系统(CRM、ERP、知识库)
- AI 可以查询客户数据、生成报告、更新系统
开发者使用:
- Claude Code 通过 MCP 连接 GitHub、数据库、开发工具
- 实现真正的“AI 编程助手”
当前状态(2026.2)
- 已有 75+ 官方连接器
- Python 和 TypeScript SDK 月下载量 9700 万+
- 已被 Linux 基金会接管,成为中立开源标准
四、Skill:给 AI 装的技能包
什么是 Skill
Skill 是给 AI 配置的特定能力或工作流程,让它能更好地完成某类任务。类比:
- 传统 AI:通用工人,什么都能干一点
- 装了 Skill 的 AI:专业技工,某个领域特别擅长
Skill 的不同形式
Custom GPT(OpenAI)
- 创建定制版 ChatGPT
- 通过 Instructions 定义行为
- 可以上传 Knowledge 文件
- 可以添加 Actions 调用外部 API
例子:
- “Python 编程导师”:专门教 Python,有耐心,会举例
- “小红书文案助手”:熟悉小红书风格,自动生成标题和正文
- “数据分析师”:上传公司数据,自动生成分析报告
Skill 的核心要素
- Instructions(指令):定义行为方式
- Knowledge(知识库):上传专业文档、数据、案例
- Tools/Actions(工具):调用外部功能
- Workflow(工作流):多步骤执行流程
Skill 的价值
- 效率提升:重复任务一键完成
- 知识沉淀:把专业经验固化为可复用流程
- 团队协作:分享最佳实践
- 降低门槛:新手也能使用专家级工作流
五、其他关键概念
Prompt Engineering(提示词工程)
通过精心设计输入文本来引导 AI 生成更准确的输出。这是使用 AI 的基础技能。
核心要素:
- 清晰的指令
- 必要的上下文
- 指定输出格式
给出示例例子对比:
- ❌ 差提示词:“写个文案”
- ✅ 好提示词:“为一款面向 25-35 岁职场女性的护肤品写一段小红书风格的文案,突出天然成分和快速吸收,150 字左右,语气轻松活泼”
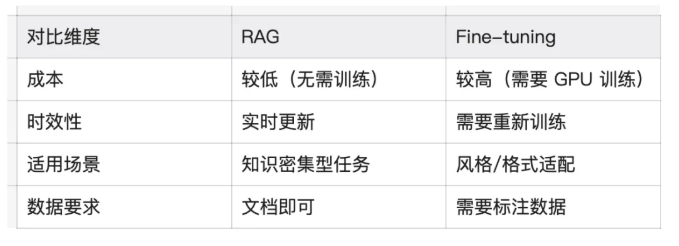
RAG(检索增强生成)
让 AI 在回答问题时,先从外部知识库检索相关信息,然后基于检索到的内容生成回答。
解决的问题:
- AI 知识过时
- AI 不知道最新信息
- AI 不知道你的私有数据
工作流程:
- 用户提问:“公司上季度的销售数据是多少?”
- 在公司文档库中搜索相关报告
- 将找到的数据添加到提示词中
- AI 基于实际数据生成回答
关键技术:
- Embedding(嵌入):将文本转换为数字向量
- Vector Database(向量数据库):存储和检索向量数据
- Semantic Search(语义搜索):按含义而非关键词搜索
Fine-tuning(微调)
在预训练模型的基础上,用特定领域的数据进行额外训练,使模型更适应特定任务或风格。
类比:
- 预训练模型:大学毕业生(有通用知识)
- 微调:入职培训(学习公司特定流程和术语)
适用场景:
- 特定领域的专业术语(医疗、法律、金融)
- 特定的写作风格或语气
LLM(大语言模型)
通过海量文本数据训练的深度学习模型,能够理解和生成人类语言。是现代 AI 应用的核心。
代表模型:
- GPT 系列(OpenAI)
- Claude 系列(Anthropic)
- Gemini(Google)
- 文心一言(百度)
- 通义千问(阿里)
Embedding(嵌入/向量化)
将文本转换为数字向量的过程,使计算机能够“理解”文本的含义并进行数学运算。
例子:
- 文本:“苹果很好吃” → 向量:[0.2, 0.8, 0.1, ……, 0.5]
- 相似的文本会有相似的向量
应用:
- 语义搜索(找意思相近的内容)
- 推荐系统(找相似的文章/商品)
- RAG 系统(检索相关文档,使用检索增强生成)
Vector Database(向量数据库)
专门存储和检索向量数据的数据库,支持高效的相似度搜索。
常见产品:
- Pinecone
- Weaviate
- Chroma
- Milvus
- Qdrant
为什么需要:
传统数据库按关键词搜索,向量数据库按“含义”搜索,能找到语义相似但用词不同的内容。
Context Window(上下文窗口)
AI 模型一次能“看到”的最大文本量,这是以 Token 计来计算的,看过我们文章第一部分的应该知道为什么要先解释Token了吧。超过这个限制,模型就会“忘记”最早的内容。
不同模型的窗口大小:
- GPT-3.5:4K-16K tokens
- GPT-4:8K-128K tokens
- Claude 3:200K tokens
- Gemini 1.5 Pro:1M tokens(100 万),所以Gemini的记忆力是最强的
影响:
- 窗口越大,能处理的文档越长
- 窗口越大,成本越高
- 长对话可能超出窗口限制
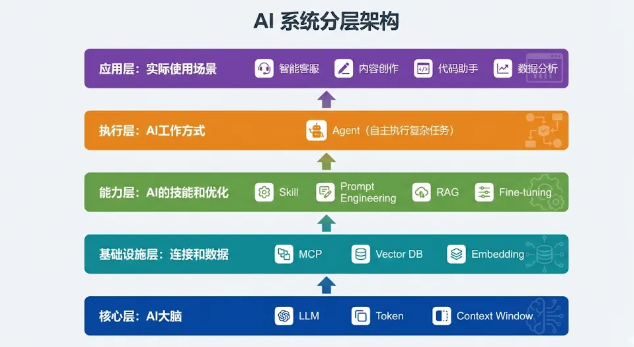
六、概念之间的关系
技术栈层次(从底层到应用层)
优化 AI 输出的三种路径
路径 1: Prompt Engineering(优化输入)
- 设计更好的提示词
- 成本:最低
- 速度:最快
- 适用:通用任务
路径 2: RAG(用检索增强生产来补充知识)
- 从外部获取最新信息
- 成本:中等
- 速度:较快
- 适用:知识型任务
路径 3: Fine-tuning(改变模型)
- 用专业数据重新训练
- 成本:最高
- 速度:慢
- 适用:专业领域
完整的 AI 应用工作流核心组合模式
1. RAG + Prompt Engineering(最常用)
- Prompt 设计检索策略
- RAG 提供知识支持
- 适合:知识问答、文档分析
2. Fine-tuning + RAG(专业应用)
- Fine-tuning 适配领域术语
- RAG 提供最新信息
- 适合:医疗、法律等专业领域
3. Agent + MCP + Skill(自动化)
- Agent 自主规划
- MCP 连接工具
- Skill 提供方法论
- 适合:复杂任务自动化
4 . 全栈组合(企业级应用)
这些概念不是孤立的,而是相互配合的。
- LLM是大脑
- Token是计量单位
- Prompt Engineering是如何提问
- RAG是如何补充知识
- Fine-tuning是如何定制模型
- Skill是如何封装能力
- MCP是如何连接外部
- Agent是如何自主执行
理解这些概念,差不多就能看懂大部分 AI 产品的技术文档,也能更好地使用 AI 工具。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。