



Pythia-RAG 统一多模态知识图谱的检索增强实践

核心亮点
机制创新:告别昂贵的微调。 探讨了如何不更新模型参数、不依赖海量显存,仅通过“重塑推理时注意力流(Rewiring Attention)”,实现比传统微调更高效、无灾难性遗忘的文本知识融合(KGA)。
范式突破:打破图文检索壁垒。 揭示了在多模态RAG中,通过构建“统一多模态知识图谱(Unified Multimodal KG)”与“两阶段去噪检索”,如何解决视觉噪声干扰,实现跨模态语义的深度对齐(Pythia-RAG)。
演进路线:从单模态机制到多模态数据。 完整展示了大模型外部知识增强的技术进阶路径——从轻量化的推理机制改革,走向复杂的多模态数据统一建模。
一、 背景:打破静态参数与单一模态的桎梏
在当今的大语言模型(LLM)时代,尽管模型展现出了惊人的通用推理能力,但“知识过时”依然是横亘在工业落地前的一座大山。为了解决这一问题,引入外部知识图谱(Knowledge Graph, KG)已成为行业共识。然而,现有的解决方案大多面临着两个维度的局限性:
1.融合机制的僵化:传统的微调( Fine-tuning)成本高昂且易导致灾难性遗忘,而主流的RAG(检索增强生成)往往受限于上下文窗口,且简单的拼接容易造成注意力分散。我们急需一种更轻量、更符合认知直觉的文本知识融合机制。
2.模态单一的局限:现实世界的知识不仅仅是文本,还包含大量的图像、图表等视觉信息。如何让大模型同时理解并利用多模态知识进行复杂问答,是下一代AI系统的关键挑战。
基于此,我们团队在近期连续取得了突破性进展,分别从“推理时注意力重塑(KGA)”和“统一多模态知识检索(Pythia-RAG)”两个方向,提出了全新的解决方案。前者通过创新性的KGA框架,在不训练参数的情况下实现了高效的文本知识融合;后者则进一步拓展边界,通过Pythia-RAG框架将视觉与文本知识统一建模,显著增强了模型的多模态问答能力。
关键词:知识图谱增强;大语言模型;注意力重塑;动态知识更新,多模态知识图谱
二、KGA核心技术概述
针对文本知识的融合痛点,我们首先介绍KGA(Knowledge Graph-guided Attention,知识图谱引导注意力机制),这是一种无需训练、在推理时即可将外部知识图谱动态融合进大语言模型的全新框架。针对当前大模型面临的知识过时、微调成本高昂以及灾难性遗忘等痛点,KGA受人类认知神经科学启发,通过创新性地“重塑”Transformer内部的自注意力机制,实现了双通路的知识聚合。实验表明,KGA不仅在知识问答、知识推理和知识编辑等任务上显著优于现有的上下文学习(ICL)和微调方法,还能通过减少不必要的token之间的交互来提升融合效率,为大模型在动态变化的环境中的落地应用提供了轻量级、高可用的解决方案。
2.1、KGA是首个基于认知双通路注意力理论的推理时知识融合框架,其设计理念回归了大模型处理信息的本质——Token间的交互。
该框架具有以下四大核心技术优势:
(1)认知启发的双通路机制
自下而上的融合通路(Bottom-Up): 模拟人脑受刺激驱动的注意力过程。将输入的查询(Query)作为刺激信号,驱动模型主动从外部知识三元组中聚合语义信息,实现知识的初步注入。
自上而下的引导通路(Top-Down): 模拟人脑的目标导向验证过程。模型利用知识三元组反向探测输入上下文,计算每个三元组的相关性权重,从而精准过滤噪声,仅保留对当前推理有价值的核心知识。
(2)零参数、无损植入
无需训练(Training-Free): KGA直接复用预训练模型原本的投影矩阵(Query/Key/Value),无需任何额外的参数训练或适配器(Adapter)。
避免灾难性遗忘: 由于不修改模型权重,KGA完美保留了基座模型的通用语言能力和指令遵循能力,在知识编辑任务中实现了100%的非相关知识保留率(Locality)。
(3)即插即用的动态更新
实时性:面对不断变化的Web知识(如新闻、政策变动),只需在输入端更新三元组数据,模型即可实时获得最新知识,无需重新部署或微调。
灵活性:能够无缝集成到Llama 3、Qwen 2.5等各类主流Transformer架构的模型中。
(4)高效的计算性能
告别“上下文堆砌”:与将所有知识拼接在输入端的上下文工程不同,KGA通过重塑注意力流,避免了无效的Token交互。
资源友好: 实验数据显示,在处理大量外部知识时,KGA的显存占用和推理延迟低于传统的上下文工程,缓解了长文本带来的算力瓶颈。
2.2、KGA与传统方法的深度对比
KGA在设计理念和实际效果上,均突破了现有知识增强方法的局限:
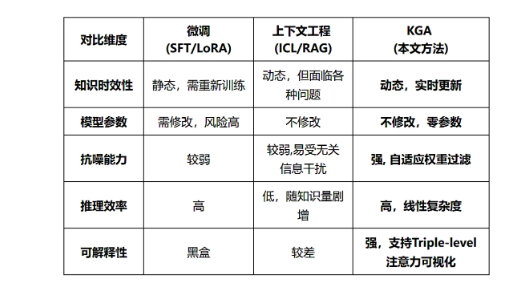
2.3、KGA的工业应用价值
KGA框架不仅具有学术创新性,更解决了工业界在大模型落地时的核心痛点,具有广泛的应用前景。
2.3.1 搜索引擎与实时问答
在Web搜索场景中,信息每秒都在更新。KGA允许搜索引擎将检索到的最新结构化数据直接注入大模型,无需等待模型迭代,即可生成准确、时效性强的回答,显著减少“幻觉”现象。
2.3.2 垂直领域知识库构建(金融/医疗/法律)
低成本部署: 企业无需为每周更新的法规或市场数据进行昂贵的模型微调。
精准溯源: KGA的可解释性机制允许用户查看模型究竟关注了哪条知识,这对于对准确性要求极高的金融和法律领域至关重要。
2.3.3 端侧设备与低算力场景
得益于其高效的显存利用率,KGA使得在显存受限的端侧设备(如个人电脑、手机)上运行具备海量外部知识的“博学”大模型成为可能。实验表明,即便是0.5B参数的小模型,在搭载KGA后也能达到甚至超越大模型的知识推理水平。
2.4、基于多数据集的评测
研究团队在Knowledge Graph QA (KGQA)、Knowledge Graph Reasoning 以及 Knowledge-based Model Editing (知识编辑) 三大任务、四个基准数据集上对KGA进行了全面评估。
2.4.1 知识问答与推理表现
在SimpleQuestions和PathQuestion数据集上,KGA展现了超越SFT和上下文工程的卓越性能。
小模型逆袭:搭载KGA的Qwen2.5-0.5B-Instruct模型在多跳推理任务上达到了96%的准确率,远超同尺寸的上下文工程方法(20%)。
跨模型通用性:无论是Llama 3 (8B) 还是 Qwen 2.5 (7B/72B),KGA均能带来稳定的性能提升。
2.4.2 知识编辑任务的进展
在模拟真实世界连续知识更新的ZsRE和CounterFact数据集上,KGA的效果仍然让人满意:
有效性(Efficacy)提升百倍: 在CounterFact数据集上,基于Llama3-8B的上下文知识编辑IKE有效性仅为0.55%,而KGA将其提升至67%。
完美的局部性(Locality): 在注入新知识的同时,KGA对模型原有无关知识的干扰为0,优于所有微调基线(如ROME, MEMIT)。
2.4.3 鲁棒性与效率
抗噪测试: 随着无关噪声三元组数量的增加,ICL方法的性能直线下降,而KGA凭借“自上而下”的门控机制,性能曲线保持平稳,展现了极强的抗干扰能力。
三、 Pythia-RAG:统一多模态图谱,重构多模态问答体验
虽然KGA在文本领域表现优异,但为了应对更复杂的真实世界场景,我们将视野拓展到了多模态领域,推出了全新的Pythia-RAG框架。这是一个基于统一多模态知识图谱(Unified Multimodal Knowledge Graph)的检索增强生成系统。
3.1. 核心挑战:多模态数据的异构性与噪声
在多模态问答(MMQA)中,模型不仅要处理文本,还要理解图像。传统方法往往难以在检索阶段有效对齐这两种模态,且容易引入大量的无关视觉噪声,导致生成结果不仅缺乏准确性,还可能产生视觉幻觉。
3.2. 解决方案:统一多模态图谱与两阶段检索
Pythia-RAG 提出了一种端到端的增强方案,其核心架构包含三个关键步骤:
统一多模态知识图谱构建: 不同于将图像和文本分开处理,Pythia-RAG构建了一个包含文本节点和图像节点的统一图谱。这使得系统能够在同一个语义空间内捕捉模态间的关联。
密集检索与重排序 (Dense Retrieval & Re-ranking): 为了解决噪声问题,Pythia-RAG设计了一个两阶段检索器。首先从图谱中检索相关的文本和图像实体,然后通过一个专门的重排序模块(Re-ranking)对候选证据进行过滤,确保输入给大模型的信息是高度相关的。
多模态生成: 经过过滤的多模态上下文(文本+图像)被送入大模型,模型结合自身的参数化知识与检索到的外部证据,生成最终答案。
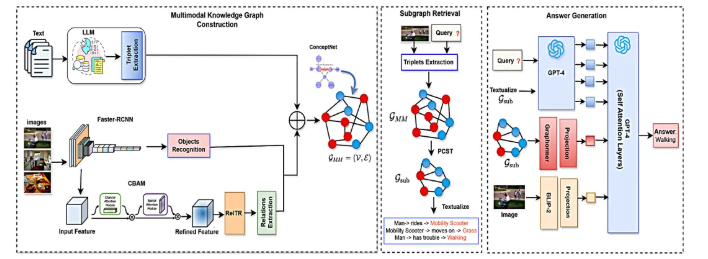
图2. Pythia-RAG框架图
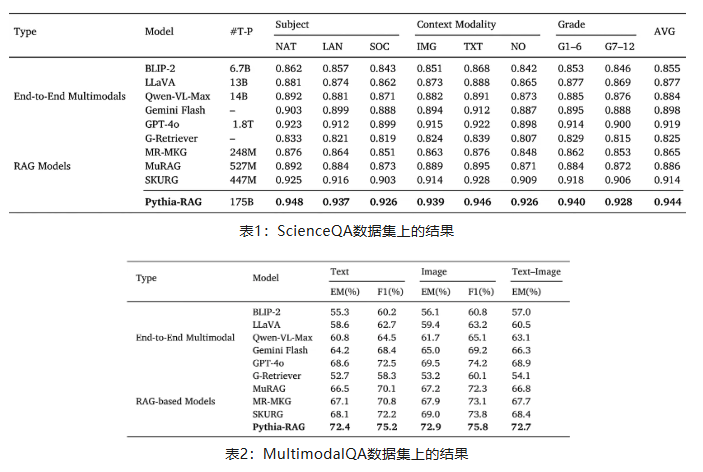
3.3. 实验表现
Pythia-RAG 在两大权威多模态问答基准数据集WebQA和MultimodalQA上进行了广泛测试。实验结果表明,Pythia-RAG 在准确率和鲁棒性上均显著优于现有的基线模型(如Flamingo等),证明了引入统一多模态图谱进行检索增强的有效性。
四、总结
从KGA到Pythia-RAG,我们展示了一条清晰的大模型外部知识增强进阶路径:
- 在机制层面: KGA证明了我们不需要昂贵的微调,仅通过巧妙地重塑注意力机制(Rewiring Attention),就能在推理时高效、精准地融合文本知识。
- 在数据层面: Pythia-RAG证明了知识增强的边界不应局限于文本。通过构建统一的多模态知识图谱并结合精细的检索-重排序策略,我们可以让大模型具备“图文并茂”的认知能力。
- 这两项工作互为补充,共同构建了一个“机制轻量化、模态多样化”的AI新未来。未来,我们将致力于将KGA的推理时融合机制与Pythia-RAG的多模态检索能力进一步结合,打造一个真正全能、实时更新且可信赖的知识图谱融合系统。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。