



什么是DeepSeek-OCR?
首先,不要被这个名字骗了,你可能用过OCR(文字识别)工具,比如手机拍一下书页,就能把图片上的字转换成可编辑的文本。但 DeepSeek-OCR 不只是简单的OCR——它更像是一个「文字压缩大师」,能让AI记住更多内容,理解更长的文章,甚至解决大模型最头疼的「失忆问题」。
虽然名为 OCR,但 DeepSeek-OCR 并非传统意义上的文字识别工具。它确实具备 OCR 功能 —— 能将图片文字转换为可编辑文本,且处理复杂排版的金融报告时,不仅能提取文字,还能将图表转化为可编辑的 Markdown 代码,远超普通 OCR 软件。 但其核心突破在于上下文光学压缩技术。当前大语言模型处理长文本时,需将文字转为 Token,并随文本长度呈平方级增加计算量,导致处理几十万字内容时算力崩溃。传统优化算法治标不治本,而 DeepSeek-OCR 另辟蹊径:
- 图像化压缩:将长文本转化为二维图像,利用 “上下文光学压缩” 技术,把百万级 Token 压缩成视觉 Token,解决长文本内存爆炸问题。
这种 “看图像” 代替 “读文字” 的方式,重构了长文本处理逻辑,正是 DeepSeek-OCR 的革命性所在。
是OCR,因为它确实是顶级的“文字搬运工”
说它是,理由很简单:它干的确实是传统OCR(光学字符识别)的活。
传统的OCR任务特别纯粹:把图片上的字,变成电脑里可编辑、可复制的数字文本。回想没有OCR的时代,你想把书上的好段落录入电脑,只能一个字一个字地敲。敲几句话还行,让你敲一份合同,是个人都得疯。
OCR的出现解决了这个问题,拍张照片就能提取文字,简单高效。而DeepSeek-OCR确实具备强大的OCR功能,并且做得非常出色。
但它的强大,远超你的想象:
想象一张典型的金融研究报告,里面有文字、有图表、有复杂排版。
- 传统OCR处理它:会精准地把所有文字抠出来,变成一个TXT文档。然后,就没有然后了。
- DeepSeek-OCR处理它:会直接生成一个结构完整的Markdown文档。文字是文字,标题是标题,最关键的是,里面的图表会被它用代码重新绘制,变成一个可编辑、可引用的表格。
比如:你拍一张金融研报,DeepSeek-OCR不仅能提取文字,还能把里面的股票数据自动整理成表格,方便你直接分析。

虽然这已经足够牛逼了。但是,这玩意儿的能耐,远不止我们传统意义上理解的OCR。
不只是OCR,它是AI的“记忆压缩神器”
它还有一个更重要的、听起来有点抽象的功能:压缩。
在理解“压缩”之前,我们得先明白当前所有大语言模型(从GPT-3.5到如今的各类模型)共同面临的、几乎无解的噩梦:长文本处理。
别看AI现在能聊天、能写作,仿佛无所不能,但你一旦丢给它一本几十万字的书让它理解总结,它基本都会“炸掉”。
为什么?
根源在于AI理解文字的方式与我们人类截然不同。
- 我们看书:是“一目十行”,整体感知。
- AI读文字:需要把每个字、词转换成“Token”(可理解为数据字节)。而且,主流AI架构有一个致命缺陷:它在读每一个新词时,为了理解上下文,都需要把这个新词与前面所有出现过的词都建立一次联系。
这就导致处理Token的计算量,随着文本长度的平方急剧增加。
这就像一个派对:
- 10个人,每个人相互打招呼,需要大约45次互动,还行。
- 100个人,每个人相互打招呼,就需要近5000次互动,这派对基本就废了。
这就是技术上所谓的**计算复杂度O(n²)**。成本是指数级增长的,谁都扛不住。
因此,整个AI界都在死磕一个问题:如何让AI又快又便宜地搞定长上下文?大家想了各种办法,如滑动窗口、稀疏注意力等。但这些方案,都像是在给一辆漏油的破车换更好的轮胎、贴更骚的膜,却解决不了发动机的根本问题。
DeepSeek-OCR的降维打击:从“读字”到“看图”
而DeepSeek这次的思路,根本就没管那辆漏油的破车,而是直接换了一辆新能源。
它提出了一个革命性质问:“我们为什么非要让AI一个字一个字地读呢?我们能不能让它像我们人一样,‘看’?”
具体方案是:不再把一本300页的书转换成几十万个Token的文本文件喂给AI,而是直接把这本书拍成一张张照片(图像文件),然后让AI去“看”这些图。
你可能会觉得这是脱裤子放屁——照片不也是由像素组成的吗?信息量不是更大了?
但关键点在于:图像是二维的,而文字是一维的。
- 一维文字:像一根无限长的薯条,你必须从头吃到尾,一个字节都不能少。
- 二维图像:像一张大饼,你一眼扫过去,全貌尽收眼底。
DeepSeek-OCR干的就是这件事:将文字“压缩”成图像。这个过程,在论文中被称为 “上下文光学压缩”。
该表格测试了 DeepSeek-OCR 在 Fox 基准的 600-1300 词元全英文文档上的视觉 - 文本压缩比,呈现了不同文本词元区间下,视觉词元为 64 和 100 时的精确率、压缩比及对应页数情况

一个场景,让你彻底明白
假设你与AI助手聊了三天三夜,共1000轮对话,占用了几百万Token。
- 传统AI:当你问“我三天前说的第一件事是啥?”,它必须将1000轮对话的全部记录装入上下文窗口才能查找。这会瞬间撑爆内存与算力,因此现实中AI常常“失忆”,只能记住最近几十轮。
- DeepSeek-OCR的方案:
当你再次提问:“我三天前说的第一件事是啥?”时,它的解码器(DeepSeek-3B模型)已经通过OCR任务学会了“看懂”这些视觉Token,能够将其解码还原成原文。于是,它“瞥了一眼”那些视觉Token,找到了三天前的第一句话,准确回答了你。
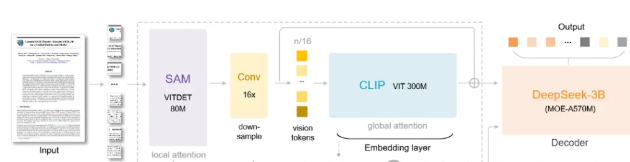
DeepSeek-OCR架构图
这,就是DeepSeek-OCR的完整架构,只需记住:其核心是压缩。
总结:DeepSeek-OCR = 超级OCR + 记忆革命
- 对普通用户:它是史上最强的OCR工具,能智能还原文档结构和内容。
- 对AI行业:它是突破性的上下文处理新范式,解决了长文本处理的难题。
这不仅是技术升级,更是认知方式的革命!
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。