



国产大模型如何实现算力突围?
在大模型算力军备竞赛愈演愈烈的当下,Deepseek作为国产阵营的一员实现了差异化破局。
Deepseek通过架构、工程、训练全链条创新,以显著降低的训练成本实现了与国际一线模型相当的推理能力,更悄悄改写了行业对算力利用、模型训练的固有认知。与此同时,作为AI场景落地的终极形态,AI Agent的发展卡点与突破方向也逐渐清晰。
本文将基于海创汇专业研究报告《DeepSeek创新研究&AI Agent分析Ⅱ》,为读者系统拆解Deepseek的技术创新、产业影响以及AI Agent的发展。
一、三大技术创新:高效释放算力价值
DeepSeek的突围并非单点突破,而是架构算法、工程优化、训练方式三大维度的系统性革新,核心目标是最大化算力利用率与探索AGI路径。子复合材料上仍依赖进口,自研材料的耐用性还需验证。
1.架构升级:
MoE+MLA,效率与性能双提升
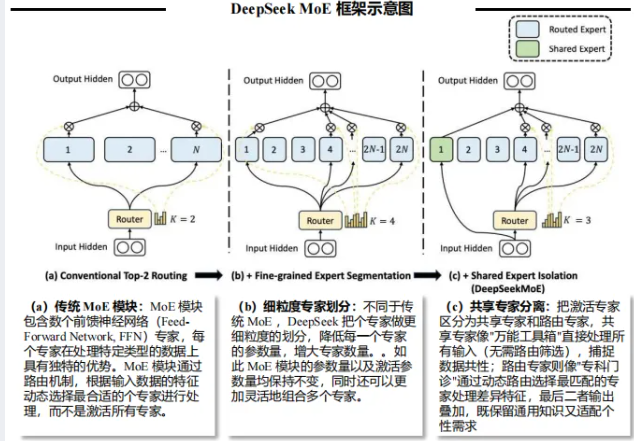
MoE混合专家架构:打破传统全能专家模式,采用海量小专家+通才调度设计——将全能型人才拆解为专业细分团队与统筹协调层,每个专业团队聚焦特定知识模块,统筹层负责协同组合。配合无辅助损失负载均衡技术,解决MoE训练的路由崩溃难题,既减少4倍以上计算量,又避免资源浪费。
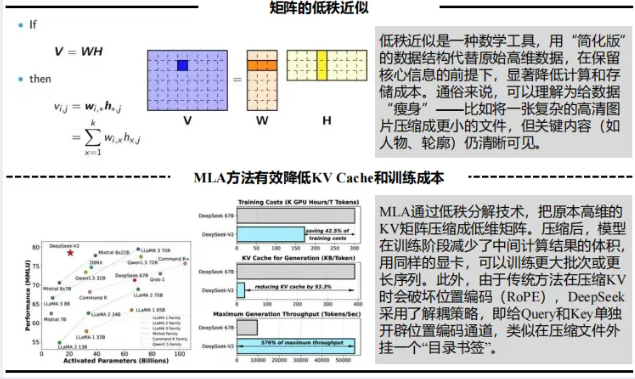
MLA多头隐式注意力:通过低秩压缩技术优化KV缓存,对高维数据进行精准降维提质,在减少显存占用的同时保留核心性能,让长序列数据处理效率提升2-4倍。该技术首次在DeepSeek-V2中引入,是目前开源模型中优化KV缓存的最优方案之一。
2.工程优化:
软硬件协同,充分释放硬件潜力
DeepSeek的工程团队通过四大核心技术,将GPU利用率提升至77%,实现硬件性能的高效发挥:
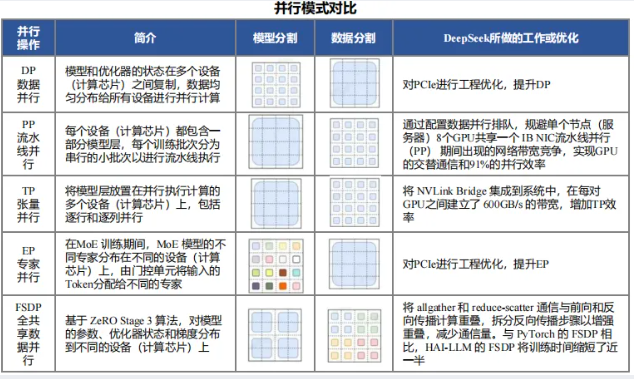
HAI-LLM框架:支持数据并行、张量并行等多种并行模式,配合两层FatTree拓扑硬件架构,相比传统集群节省40%互连成本;
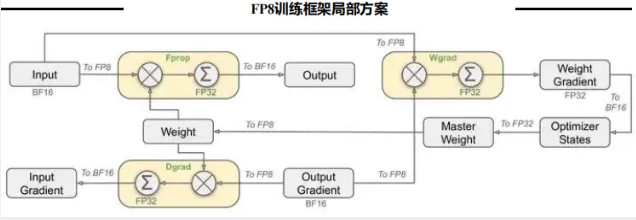
FP8训练框架:攻克低精度训练失准难题,通过分块处理、关键模块高精度保护、动态误差补偿三大策略,在提升计算速度的同时保障模型精度;
DualPipe优化:实现前向与后向传播同步调度,减少流水线气泡现象,大幅提升多卡并行的资源利用率;

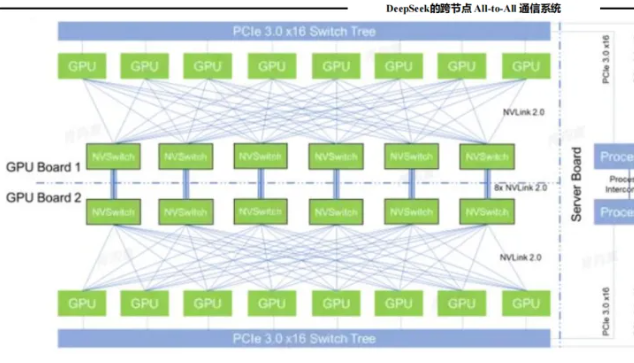
跨节点All-to-All通信:构建高效的通信调度体系,最大化InfiniBand与NVLink带宽利用率,通过warp专用化技术与PTX指令优化,减少通信对计算单元的干扰。
3.训练革命:
从SFT到纯RL,探索AGI新路径
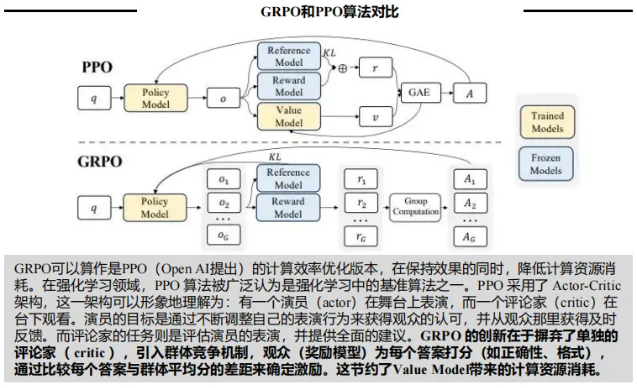
GRPO强化学习:摒弃传统PPO算法的评论家模型,通过群体竞争机制评估输出优劣,在降低显存消耗的同时提升训练稳定性;
R1-Zero纯RL训练:首创不依赖监督微调的训练模式,完全通过强化学习培养推理能力,模型自发呈现反思、自我纠错等高级认知行为,为AGI探索提供关键实践;
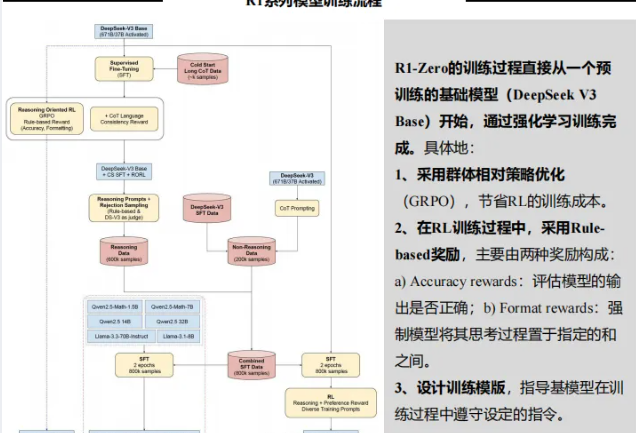
R1四阶段训练:通过冷启动SFT、推理强化学习、拒绝采样SFT、全场景对齐的迭代流程,平衡推理能力与输出可读性,解决纯RL模型的语言混杂问题;
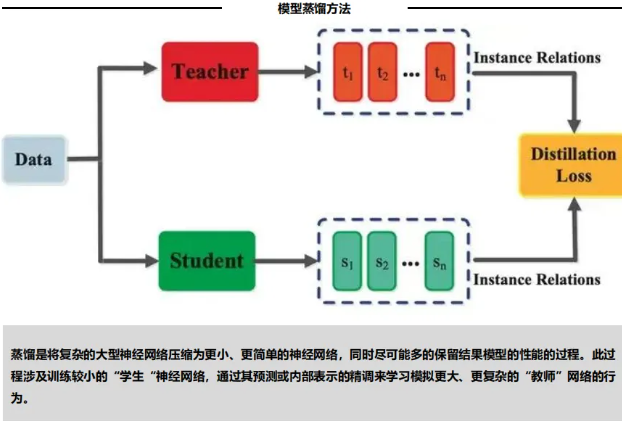
R1-Distill蒸馏:将大模型推理能力迁移至7B、14B等小参数模型,为边缘端、低资源场景提供高效推理解决方案。
二、产业影响:算力市场重构,架构格局分化
DeepSeek的创新不仅是技术突破,更在重塑行业生态格局。
1.算力效率革命:杰文斯悖论或将显现
DeepSeek将H800单卡利用率提升至77%,671B参数的R1模型单次推理仅激活37B参数,大幅降低训练与推理成本。但算力效率的提升可能刺激AI应用爆发式渗透,引发效率提升→需求扩张的杰文斯悖论,推动推理算力卡需求进入爆发周期。
2.英伟达的双刃剑:短期冲击与长期利好
短期:低成本模型动摇算力军备竞赛的市场预期,导致英伟达市盈率阶段性回落;
长期:DeepSeek为英伟达开拓了MoE开源模型新场景,B200显卡搭载DeepSeek-R1后,推理吞吐量提升25倍,每token成本降低20倍,进一步巩固英伟达生态优势。
3.架构分化:MoE与Dense各擅其场
MoE架构:适用于ToC云端通用场景,凭借高算力效率成为大厂核心选择;
Dense架构:主导ToB专业场景与端侧部署,因场景适配性强、显存需求合理,仍是当前市场主流。未来,显存-算力平衡型GPU将持续成为行业首选,大显存单卡因成本与场景适配问题难以大规模普及。
二、AI Agent:现状、卡点与未来趋势
如果说大模型是AI应用的能力下限,AI Agent就是场景落地的价值上限。但目前AI Agent仍处于极早期阶段,核心卡点集中在四大维度。
1.核心卡点:四大能力亟待突破
自主思考:多数Agent仍依赖预设规则,本质为增强型工作流,缺乏动态目标分解与环境自适应能力;
规划与工具调用:复杂任务中存在错误累积、模糊需求拆解困难等问题,虽有MCP/A2A协议解决工具孤岛,但动态决策能力仍需提升;
记忆:长期记忆易丢失、混淆,现有技术仅优化记忆效率,尚未解决意义构建层面的精准记忆难题;
多模态理解:模态割裂导致语义关联弱化,动态场景下的适配性与鲁棒性不足。
2.突破方向:技术路径逐渐清晰
自主思考:通过强化学习与推理模型深度融合,结合Agentic数据模拟训练,提升动态规划能力;
规划与工具调用:采用分层状态机设计与异常熔断机制,推动MCP与A2A协议协同融合,优化复杂任务处理流程;
记忆:构建分层记忆架构与动态权重分配机制,结合图谱增强技术提升记忆准确性与检索效率;
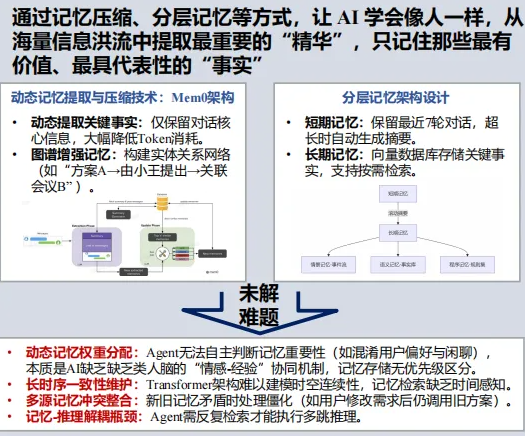
多模态理解:研发动态多模态融合技术与实时数据流对齐方案,强化跨模态语义关联与环境适应性。
3.未来趋势:从工具执行到自主服务
AI Agent将朝着端到端训练+自主进化方向演进,专业化、场景化成为核心发展路径——为金融、制造、医疗等领域定制专属Agent。最终将实现模型即产品、模型即服务的形态转变,直接为用户提供全流程解决方案,推动AI产业从技术突破走向规模化商业落地。
DeepSeek的突围证明,国产大模型无需陷入参数竞赛,通过架构、工程、训练的系统性创新,同样能实现弯道超车。其核心价值不仅在于降低了大模型的落地成本,更在于为AGI探索提供了纯RL训练的可行路径。
而AI Agent作为场景落地的终极形态,正从预设规则执行向自主智能决策演进。未来几年,谁能突破自主思考、精准记忆、多模态协同的核心卡点,谁就能掌握AI行业的下一张核心入场券。国产大模型的创新故事,才刚刚开启新的篇章。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。